 |
Index Classification |
| << Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing |
| Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes >> |

Database
Management System
(CS403)
VU
Lecture No.
37
Reading
Material
"Database
Systems Principles, Design
and Implementation" written by
Catherine Ricardo,
Maxwell
Macmillan.
"Database
Management System" by Jeffery A
Hoffer
Overview of Lecture:
o Indexes
o Index
Classification
In the
previous lecture we have discussed
hashing and collision
handling. In
today's
lecture we will discuss indexes, their
properties and
classification.
Index
In a
book, the index is an
alphabetical listing of topics,
along with the page
number
where
the topic appears. The
idea of an INDEX in a Database is
similar. We will
consider
two popular types of
indexes, and see how
they work, and why
they are
useful.
Any subset of the fields of a
relation can be the search
key for an index on
the
relation.
Search key is not the
same as key (e.g.
doesn't have to be unique
ID). An
index
contains a collection of data
entries, and supports efficient
retrieval of all
records
with a given search key
value k. typically, index also
contains auxiliary
information
that directs searches to the
desired data entries. There
can be multiple
(different)
indexes per file. Indexes on
primary key and on
attribute(s) in the
unique
constraint
are automatically created. Indexes in
databases are similar to indexes
in
books. In
a book, an index allows you
to find information quickly
without reading the
entire
book. In a database, an index
allows the database program
to find data in a
table
without
scanning the entire table.
An index in a book is a list of
words with the page
numbers
that contain each word. An
index in a database is a list of
values in a table
with
the storage locations of rows in
the table that contain
each value. Indexes can
be
270
Database
Management System
(CS403)
VU
created on
either a single column or a
combination of columns in a table
and are
implemented
in the form of B-trees. An
index contains an entry with
one or more
columns
(the search key) from
each row in a table. A
B-tree is sorted on the
search
key,
and can be searched
efficiently on any leading
subset of the search key.
For
example,
an index on columns A, B, C can be
searched efficiently on A, on A, B,
and
A, B, C.
Most books contain one
general index of words,
names, places, and so
on.
Databases
contain individual indexes
for selected types or columns of
data: this is
similar
to a book that contains one
index for names of people
and another index
for
places.
When you create a database
and tune it for performance,
you should create
indexes
for the columns used in
queries to find data.
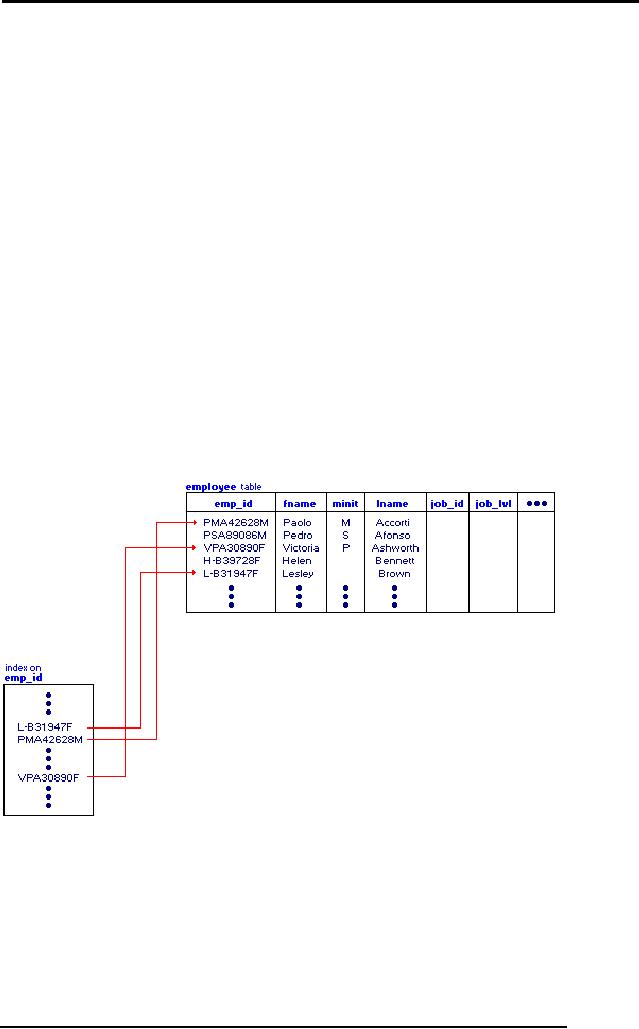
In the
pubs sample database provided with
Microsoft� SQL ServerTM
2000, the
employee
table has an index on the
emp_id column. The following
illustration shows
that
how the index stores
each emp_id value and
points to the rows of data in
the table
with
each value.
When
SQL Server executes a statement to find
data in the employee table
based on a
specified
emp_id value, it recognizes the
index for the emp_id
column and uses
the
index to
find the data. If the
index is not present, it performs a
full table scan
starting
at the
beginning of the table and
stepping through each row,
searching for the
specified
emp_id value. SQL Server
automatically creates indexes
for certain types of
271

Database
Management System
(CS403)
VU
constraints
(for example, PRIMARY KEY and
UNIQUE constraints). You can
further
customize
the table definitions by
creating indexes that are
independent of constraints.
The
performance benefits of indexes,
however, do come with a
cost. Tables with
indexes
require more storage space in
the database. Also, commands
that insert,
update,
or delete data can take
longer and require more
processing time to maintain
the
indexes. When you design
and create indexes, you
should ensure that
the
performance
benefits outweigh the extra
cost in storage space and
processing
resources.
Index
Classification
Indexes
are classified as
under:
�
Clustered
vs. Un-clustered
Indexes
�
Single
Key vs. Composite
Indexes
�
Tree-based,
inverted files,
pointers
Primary
Indexes:
Consider
a table, with a Primary Key
Attribute being used to store it as an
ordered
array
(that is, the records of the
table are stored in order of
increasing value of
the
Primary
Key attribute.)As we know,
each BLOCK of memory will store a
few records
of this
table. Since all search
operations require transfers of complete
blocks, to
search
for a particular record, we must
first need to know which
block it is stored in.
If we
know the address of the
block where the record is
stored, searching for
the
record is
very fast. Notice also that
we can order the records
using the Primary
Key
attribute
values. Thus, if we just
know the primary key
attribute value of the
first
record in
each block, we can determine
quite quickly whether a
given record can be
found in
some block or not. This is
the idea used to generate
the Primary Index file
for
the
table.
Secondary
Indexes:
Users
often need to access data on the
basis of non-key or non-unique
attribute;
secondary
key. Like student name,
program name, students enrolled in a
particular
program
.Records are stored on the basis of key
attribute; three
possibilities
�
Sequential
search
�
Sorted on
the basis of name
272

Database
Management System
(CS403)
VU
�
Sort
for command execution
A part
from primary indexes, one
can also create an index based on
some other
attribute
of the table. We describe the
concept of Secondary Indexes
for a Key
attribute
that is, for an attribute
which is not the Primary
Key, but still has
unique
values
for each record of the
table The idea is similar to
the primary index.
However,
we have
already ordered the records of
our table using the
Primary key. We
cannot
order
the records again using the
secondary key (since that
will destroy the utility
of
the
Primary Index Therefore, the
Secondary Index is a two
column file, which
stores
the
address of every tuple of
the table.
Following
are the three-implementation
approaches of Indexes:
�
Inverted
files or inversions
�
Linked
lists
�
B+
Trees
Creating
Index
CREATE [
UNIQUE ]
[
CLUSTERED | NONCLUSTERED ]
INDEX index_name
ON { table
|
view
}
(
column
[
ASC | DESC ] [ ,...n ]
We will
now see an example of
creating index as
under:
CREATE
UNIQUE INDEX pr_prName
ON
program(prName)
It can
also be created on composite attributes. We will
see it with an
example.
CREATE
UNIQUE INDEX
St_Name
ON
Student(stName
ASC, stFName DESC)
Properties
of Indexes:
Following
are the major properties of
indexes:
�
Indexes
can be defined even when
there is no data in the
table
�
Existing
values are checked on
execution of this
command
�
It
support selections of form as
under:
field
<operator> constant
273

Database
Management System
(CS403)
VU
�
It
support equality selections as
under:
Either
"tree" or "hash" indexes
help here.
�
It
support Range selections (operator is
one among <, >, <=,
>=, BETWEEN)
Summary
In
today's lecture we have
discussed the indexes, its
classification and creating
the
indexes
as well. The absence or
presence of an index does
not require a change in
the
wording
of any SQL statement. An index
merely offers a fast access
path to the data;
it
affects only the speed of
execution. Given a data
value that has been indexed,
the
index
points directly to the
location of the rows
containing that value.
Indexes are
logically
and physically independent of
the data in the associated
table. You can
create or
drop an index at anytime
without affecting the base
tables or other
indexes.
If you
drop an index, all
applications continue to work;
however, access to
previously
indexed
data might be slower. Indexes,
being independent structures, require
storage
space.
274
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, Equi–Join, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules