 |

Database
Management System
(CS403)
VU
Lecture No.
35
Reading
Material
"Database
Systems Principles, Design
and Implementation" written by
Catherine Ricardo,
Maxwell
Macmillan.
"Database
Management System" by Jeffery A
Hoffer
Overview of
Lecture
o Hashing
o Hashing
Algorithm
o Collision
Handling
In the
previous lecture we have
studied about different storage
media and the RAID
levels
and we started with file
organization. In this lecture we will
study in length
about
different types of file
organizations.
File
Organizations
This is
the most common structure
for large files that
are typically processed in
their
entirety,
and it's at the heart of
the more complex schemes. In
this scheme, all
the
records
have the same size
and the same field
format, with the fields
having fixed size
as well.
The records are sorted in
the file according to the
content of a field of a scalar
type,
called ``key''. The key must
identify uniquely a records, hence
different record
have
diferent keys. This
organization is well suited
for batch processing of the
entire
file,
without adding or deleting
items: this kind of
operation can take advantage
of the
fixed
size of records and file;
moreover, this organization is
easily stored both on
disk
and tape.
The key ordering, along
with the fixed record size,
makes this
organization
amenable
to dicotomic search. However,
adding and deleting records to
this kind of
file is a
tricky process: the logical
sequence of records tipycally matches
their
physical
layout on the media storage, so to
ease file navigation, hence
adding a record
and
maintaining the key order
requires a reorganization of the
whole file. The
usual
solution
is to make use of a "log
file'' (also called
"transaction file''), structured as
a
260

Database
Management System
(CS403)
VU
pile, to
perform this kind of
modification, and periodically
perform a batch update
on
the
master file.
Sequential
files provide access only in
a particular sequence. That
does not suit
many
applications
since it involves too much
time. Some mechanism for
direct access is
required
Direct
Access File
Organization:
For most
users, the file system is
the most visible aspect of an
operating system.
Files
store data
and programs. The operating
system implements the abstract concept of
a
file by
managing mass storage devices,
such as tapes and disks.
Also files are
normally
organized into directories to
ease their use, so we look
at a variety of
directory
structures. Finally, when multiple
users have access to files,
it may be
desirable
to control by whom and in
what ways files may be
accessed. This control
is
known as
file protection. Following
are the two
types:
�
Indexed
Sequential
�
Direct
File Organization
Indexed
sequential file:
An index
file can be used to
effectively overcome the
above-mentioned problem,
and
to speed
up the key search as well.
The simplest indexing
structure is the
single-level
one: a
file whose records are pair's
key-pointer, where the
pointer is the position
in
the data
file of the record with
the given key. Only a
subset of data records,
evenly
spaced
along the data file, are
indexed, so to mark intervals of data
records. A key
search
then proceeds as follows: the
search key is compared with
the index ones to
find
the highest index key
preceding the search one,
and a linear search is
performed
from
the record the index
key points onward, until
the search key is matched or
until
the
record pointed by the next
index entry is reached. In spite of
the double file
access
(index +
data) needed by this kind of
search, the decrease in
access time with
respect
to a
sequential file is
significant.
A type of
file access in which an
index is used to obtain the
address of the block
which
contains the required
record. An index file can be
used to effectively to
speed
up the
key search as well. The
simplest indexing structure is
the single-level one:
a
261

Database
Management System
(CS403)
VU
file
whose records are pairs key-pointer,
where the pointer is the
position in the data
file of
the record with the
given key. Only a subset of
data records, evenly
spaced
along
the data file, are
indexed, so to mark intervals of data
records.
A key
search then proceeds as
follows: the search key is
compared with the
index
ones to
find the highest index
key preceding the search
one, and a linear search
is
performed
from the record the
index key points onward,
until the search key
is
matched or
until the record pointed by
the next index entry is
reached. In spite of the
double
file access (index + data)
needed by this kind of search,
the decrease in
access
time
with respect to a sequential
file is significant.
Consider,
for example, the case of
simple linear search on a
file with 1,000
records.
With
the sequential organization, an average
of 500 key comparisons are
necessary
(assuming
uniformly distributed search
key among the data ones).
However, using
and
evenly spaced index with
100 entries, the number of
comparisons is reduced to 50
in the
index file plus 50 in the
data file: a 5:1 reduction in
the number of
operations.
This
scheme can obviously be
hyerarchically extended: an index is a
sequential file in
itself,
amenable to be indexed in turn by a
second-level index, and so
on, thus
exploiting
more and more the
hyerarchical decomposition of the
searches to decrease
the
access time. Obviously, if
the layering of indexes is pushed
too far, a point is
reached
when the advantages of indexing
are hampered by the increased storage
costs,
and by
the index access times as
well.
Indexed:
Why
using a single index for a
certain key field of a data
record? Indexes can
be
obviously
built for each field
that uniquely identifies a
record (or set of records
within
the
file), and whose type is
amenable to ordering. Multiple
indexes hence provide
a
high
degree of flexibility for accessing
the data via search on
various attributes;
this
organization
also allows the use of
variable length records (containing
different
fields).
It should
be noted that when multiple
indexes are are used
the concept of sequentiality
of the
records within the file is
useless: each attribute
(field) used to construct
an
index
typically imposes an ordering of its
own. For this very
reason is typicaly
not
possible
to use the ``sparse'' (or
``spaced'') type of indexing previously
described. Two
262

Database
Management System
(CS403)
VU
types of
indexes are usually found in
the applications: the
exhaustive type,
which
contains
an entry for each record in
the main file, in the
order given by the
indexed
key,
and the partial type,
which contain an entry for
all those records that contain
the
chosen
key field (for variable
records only).
Defining
Keys:
An
indexed sequential file must
have at least one key. The
first (primary) key
is
always
numbered 0. An indexed sequential
file can have up to 255
keys; however, for
file-processing
efficiency it is recommended that you
define no more than 7 or 8
keys.
(The
time required to insert a
new record or update an
existing record is
directly
related
to the number of keys
defined; the retrieval time
for an existing
record,
however,
is unaffected by the number of
keys.)
When
you design an indexed
sequential file, you must
define each key in
the
following
terms:
Position
and size
�
Data
type
�
Index
number
�
Options
selected
�
When
you want to define more
than one key, or to define
keys of different data
types,
you must
be careful when you specify
the key fields. The
next few subsections
describe
some considerations for
specifying keys. In Indexed
sequential files
following
are ensured:
�
New
records are added to an overflow
file
�
Record in
main file that precedes it
is updated to contain a pointer
to
the
new record
�
The
overflow is merged with the
main file during a batch
update
�
Multiple
indexes for the same
key field can be set up to
increase
efficiency
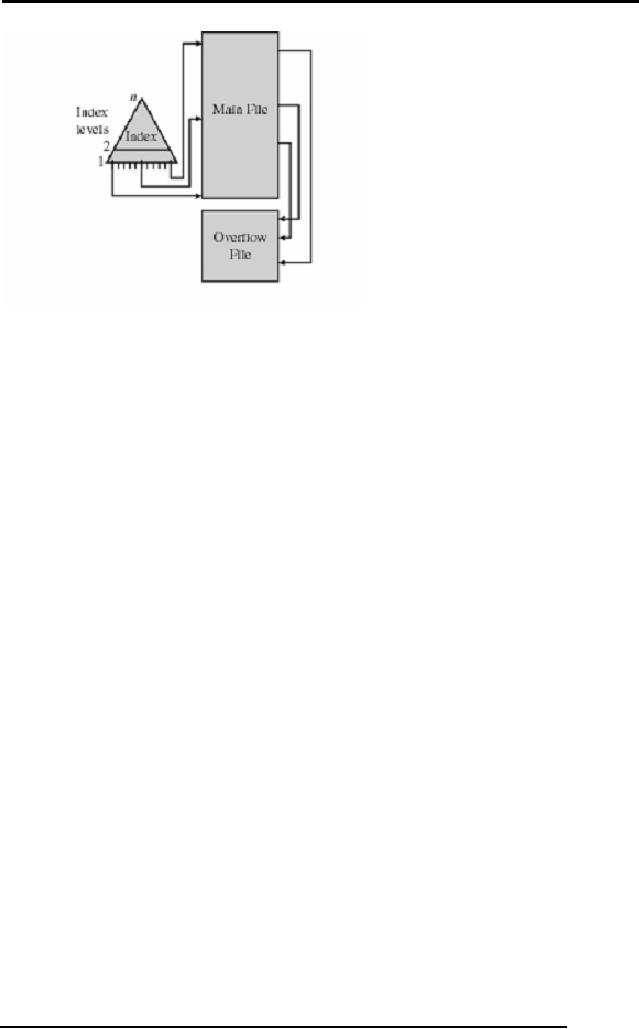
The
diagram of Index sequential
file is as under:
263
Database
Management System
(CS403)
VU
Indexed
Sequential Summary:
Following
are salient features of Indexed
sequential file
structure:
Records
are stored in sequence and
index is maintained.
Dense
and nondense types of indexes
are maintained.
Track
overflows and file overflow
areas are ensured.
Cylinder
index increases the
efficiency .
264
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, Equi–Join, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules