 |
Lecture
Handout
Data
Warehousing
Lecture
No. 07
De-Normalization
Striking a
balance between "good" &
"evil"
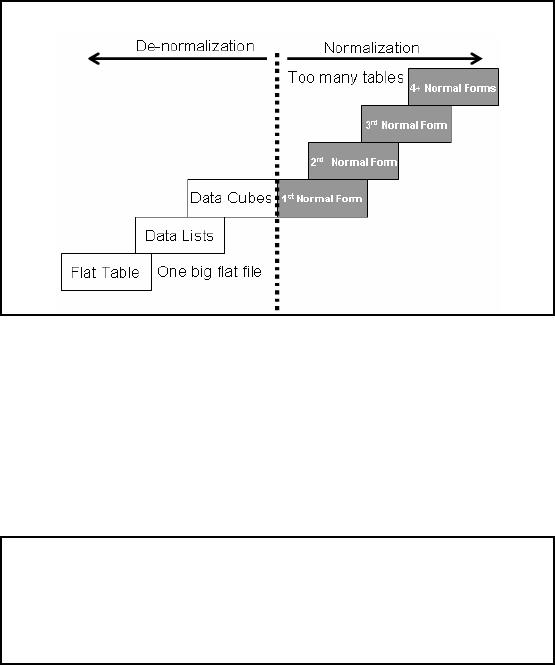
Figure-7.1:
Striking a balance between
normalization and
de-normalization
There
should be a balance between normalized
and de -normalized forms. In a fully
normalized
form, too
many joins are required and
in a totally de -normalized form, we have a big,
wide single
table.
Database should be aligned someplace in
between so as to strike a balance,
especially in the
context of
the queries and the
application domain.
A "pure"
normalized design is a good
starting point for a data
model and is a great thing
to do and
achieve in
academia. However, as briefly
mentioned in the previous lecture, in
the reality of the
"real
world", the enhancement in performance
delivered by some selective de
-normalization
technique
can be a very valuable tool.
The key to success is to
undertake de-normalization as a
design
technique very cautiously
and consciously. Do not let
proliferation of the technique
take
over
your data warehouse or you
will end up with a single
big flat file!
What is
De-Normalization?
�
It is not chaos,
more like a "controlled
crash" with the aim of performance
enhancement
without
loss of information.
�
Normalization is a
rule of thumb in DBMS, but
in DSS ease of use is
achieved by way of
denormalization.
40
�
D
e-normalization comes in many
flavors, such as combining
tables, splitting
tables,
adding data
etc., but all done very
carefully.
`Denormalization'
does not mean that anything
and everything goes. Denormalization
does not
mean
chaos or disorder or indiscipline. The development of
properly denormalized data
structures
follows software
engineering principles, which insure that
information will not be lost. De
-
normalization is
the process of selectively transforming normalized
relations into un
-normalized
physical record
specifications, with the aim of reducing
query processing time.
Another
fundamental
purpose of denormalization is to reduce
the number of physical tables,
that must be
accessed to
retrieve the desired data by
reducing the number of joins required to answer a
query.
Some
people tend to confuse dimensional
modeling with de-normalization.
This will become
clear when we
will cover dimensional modeling, where
indeed tables are collapsed
together.
Why
De-Normalization in DSS?
�
Bringing "close"
dispersed but related data
items .
�
Query
performance in DSS significantly
dependent on physical data
model.
�
Very early
studies showed performance difference in
orders of magnitude for
different
number
de-normalized tables and rows per
table.
�
The
level of de-normalization should be carefully
considered.
The
efficient processing of data
depends how close together
the related data items
are. Often all
the
attributes that appear
within a relation are not
used together, and data
from different relations
is needed
together to answer a query or produce a
report. Although normalized relations
solve
data
maintenance anomalies (discussed in
last lecture), however,
normalized relations if
implemented one
for one as physical records,
may not yield efficient data
processing times. DSS
query performance is a
function of the performance of every
component in the data
delivery
architecture,
but is strongly associated with
the physical data model.
Intelligent data modeling
through the
use of techniques such as
de-normalization, aggregation, and partitioning,
can
provide
orders of magnitude performance gains
compared to the use of normalized
data
structures.
The
processing performance between totally
normalized and partially normalized
DSSs can be
dramatic.
Inmon (grand father of data warehousing)
reported way back in 1988 through a
study,
by quantifying
the performance of fully and
partially normalized DSSs. In his
study, a fully
normalized DSS
contained eight tables with
about 50,000 rows each,
another partially normalized
DSS
had four tables with roughly
25,000 rows each, and yet
another partially normalized
DSS
had
two tables. The results of
the study showed that
the less than fully
normalized DSSs could
muster a
performance as much as an order of magnitude
better than the fully
normalized DSS.
Although
such results depend greatly on
the DSS and the
type of processing, yet
these results
suggest
that one should carefully
consider whether the physical
records should exactly match
the
normalized
relations for a DSS or
not?
How
De-Normalization improves
performance?
41

De-normalization specifically
improves performance by either:
�
Reducing the
number of tables and hence
the reliance on joins, which
consequently
speeds up
performance.
�
Reducing the
number of joins required during query execution,
or
�
Reducing
the number of rows to be retrieved
from the Primary Data
Table.
The higher
the level of normalization,
the greater will be the
number of tables in the DSS
as the
depth of
snowflake schema would increase.
The greater the number of
tables in the DSS,
the
more joins are
necessary for data manipulation.
Joins slow performance,
especially for very
large
tables
for large data extractions,
which is a norm in DSS not an
exception. De-normalization
reduces
the number of tables and
hence the reliance on joins,
which consequently speeds
up
performance.
De-normalization
can help minimize joins and foreign
keys and help resolve aggregates.
By
storing values
that would otherwise need to be
retrieved (repeatedly), one may be
able to reduce
the number of
indexes and even tables required to
process queries.
4
Guidelines for
De-normalization
1. Carefully do
a cost-benefit analysis (frequency of
use, additional storage, join
time).
2. Do a data
requirement and storage
analysis.
3. Weigh against
the maintenance issue of the
redundant data (triggers
used).
4. When in
doubt, don't
denormalize.
Guidelines
for Denormalization:-
Following
are some of the basic
guidelines to help determine whether it's time to denormalize
the
DSS
design or not:
1. Balance
the frequency of use of the
data items in question, the
cost of additional storage
to
duplicate
the data, and the
acquisition time of the
join.
2. Understand
how much data is involved in
the typical query; the
amount of data affects
the
amount of redundancy
and additional storage
requirements.
3. Remember
that redundant data is a performance
benefit at query time, but is a
performance
liability at
update time because each
copy of the data needs to be
kept up to date.
Typically
triggers are
written to maintain the integrity of
the duplicated data.
4.
De-normalization usually speeds up data
retrieval, but it can slow
the data modification
processes. It
may be noted that both
on-line and batch system
performance is adversely
affected
by a high
degree of de-normalization. Hence
the golden rule is: When in
doubt, don't
denormalize.
Areas
for Applying De-Normalization
Techniques
42

�
Dealing
with the abundance of star
schemas.
�
Fast
access of time series data
for analysis.
�
Fast
aggregate (sum, average
etc.) results and
complicated calculations.
�
Multidimensional
analysis (e.g. geography) in a
complex hierarchy.
�
Dealing
with few updates but many
join queries.
De-normalization
will ultimately affect the
database size and query
performance.
De-normalization is
especially useful while dealing with
the abundance of star
schemas that are
found in
many data warehouse
installations. For such
cases, de-normalization provides
better
performance and
a more natural data structure
for supporting decision making.
The goal of most
analytical
processes in a typical data warehouse
environment is to access aggregates
such as
averages,
sums, complicated formula
calculations, top 10 customers etc.
Typical OLTP systems
contain only
the raw transaction data,
while decision makers expect
to find aggregated and time
-
series
data in their data warehouse
to get the big picture through
immediate query and
display.
Important
and common parts of a data
warehouse that are a good
candidate for de -normalization
include (but are
not limited to):
�
Aggregation and
complicated calculations.
�
Multidimensional
analysis in a complex
hierarchy.
�
Few updates,
but many join
queries.
Geography is a
good example of a multidimensional
hierarchy (e.g. Province, Division,
District,
city
and zone). Basic design d
cisions for example, the
selection of dimensions, the number
of
e
dimensions to be
used and what facts to
aggregate will ultimately affect the
database size and
query
performance.
Five
principal De-normalization
techniques
1. Collapsing
Tables.
- Two
entities with a One-to-One
relationship.
- Two
entities with a Many-to-Many
relationship.
2.
Pre-Joining.
3. Splitting
Tables (Horizontal/Vertical Splitting).
4. Adding
Redundant Columns (Reference
Data).
5. Derived
Attributes (Summary, Total, Balance
etc).
Now we
will discuss de -normalization techniques
that have been commonly
adopted by
experienced
database designers. These
techniques can be classified
into four prevalent
strategies
for
denormalization which are:
1. Collapsing
Tables.
- Two
entities with a One-to-One
relationship.
43
- Two
entities with a Many-to-Many
relationship.
2.
Pre-joining.
3. Splitting
Tables (Horizontal/Vertical Splitting).
4. Adding
Redundant Columns (Reference
Data).
5. Derived
Attributes (Summary, Total, Balance
etc) .
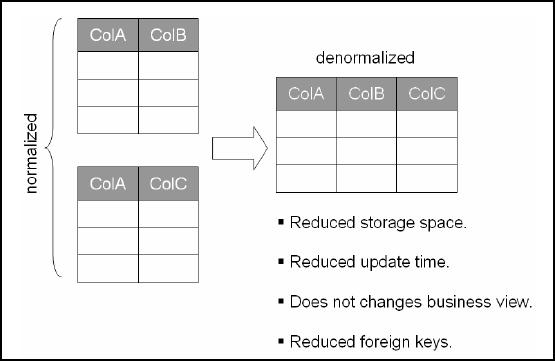
Collapsing
Tables
Figure-7.1:
Collapsing Tables
1.
Collapsing Tables
One of
the most common and
safe denormalization techniques is
combining of One-to-One
relationships.
This situation occurs when
for each row of entity A,
there is only one related
row in
entity B. While
the key attributes for
the entities may or may not
be the same, their
equal
participation in a
relationship indicates that they
can be treated as a single unit.
For example, if
users frequently
need to see COLA, CO LB,
and COLC together and
the data from the
two tables
are in a
One-to-One relationship, the solution is to collapse
the two tables into
one. For example,
SID
and gender in one table,
and SID and degree in
the other table.
In general,
collapsing tables in One-to-One relationship
has fewer drawbacks than
others. There
are several
advantages of this technique,
some of the obvious ones
being reduced storage
space,
reduced
amount of time for data
update, some of the other
not so apparent advantages are
reduced
number of
foreign keys on tables,
reduced number of indexes
(since most indexes are
created
based on
primary/foreign keys). Furthermore, combining
the columns does not change
the
business
view, but does decrease
access time by having fewer
physical objects and
reducing
overhead.
44
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orr’s Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling