 |
Data mining (DM): Knowledge Discovery in Databases KDD |
| << Join Techniques: Nested loop, Sort Merge, Hash based join |
| Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING, >> |

Lecture #
29
A Brief
Introduction to Data mining
(DM)
In our
one of previous lectures, we
discussed "putting the
pieces together". One of the
things in
those
pieces was data mining. We
mine data when we need to discover
something out of a lot. It
is a broad discipline,
dedicated courses being offered
solely. However, we will go through a
brief
introduction of
the field so that we get
ample knowledge about data
mining concepts,
applications
and
techniques.
What is
Data Mining?: Informal
"There
are things that we know
that we know...
there
are things that we know
that we don't know...
there
are things that we don't
know we don't know."
Donald
Rumsfield
US
Secretary of Defence
Lets start
data mining with a
interesting statement. Why
interesting because
the
statement
covers the overall concept
of DM and is given by a non-technical
person who
neither is a scientist
nor a data mining guru.
The statement, given by
Donald Rumsfeld,
Defense
Secretary of the USA in an
interview, is as under.
As we know,
there are known knowns.
There are things we know
that we know like you
know
your
names, your parent's names. We
also know there are
known unknowns. That is to
say, we
know
that there are some
things we do not know like
what one is thinking about
you, what you
will
eat after six days, what
will be result of a lottery and so
on. But there are also
unknown
unknowns,
the ones we don't know
that we don't know. Are they
beneficial if you know? Or it is
harmful no to
know them?
There
are also unknown knowns,
things we'd like to know,
but don't know, but know
someone
who
can doctor them and pass
them off as known knowns. To
associate Rumsfeld's above
quotation with
data mining, we identify
four core phrases as
1.
Known
knowns
2.
Known
unknowns
3.
Unknown
unknowns
4.
Unknown
knowns
The
items 1 3, and 4 deal with
"Knowns". Data
mining has relevance to the
third point in red. It is
an art of
digging out what exactly we
don't know that we must
know in our business.
The
methodology is to
first convert "unknown
unkowns" into
"known
unknowns" and
then finally to
"known
knowns".
236
What is
Data Mining?: Slightly
Informal
Tell me
something that I should
know.
When
you don't know what you
should be knowing, how do you
write SQL?
You
cant!!
Now a
slightly technical view of
DM. Not that much
technical but you may easily
understand.
Tell me
something that I should know
i.e. you ask your DWH,
data reposit ory that
tell me
something
that I don't know, or I should know.
Since we don't know what we
actually don't
know
and what we must know to know, we
can't write SQL's for
getting answers like we do
in
OLTP
systems. Data mining is an exploratory
approach, where browsing
through data using
data
mining
techniques may reveal
something that might be of
interest to the user as
information that
was
unknown previously. Hence, in data
mining we don't know the
results.
What is
Data Mining?:
Formal
�
Knowledge
Discovery in Databases (KDD).
�
Data
mining digs out valuable
non-trivial information from
large multidimensional
apparently
unrelated data bases
(sets).
�
It's
the integration of business knowledge,
people, information, algorithms,
statistics and
computing
technology.
�
Finding useful
hidden patterns and relationships in
data.
Before
looking into the technical
or formal view of DM,
consider the quote that
you might have
heard in
your childhood i.e. finding a
needle in the haystack . It is a tough
job to find a need le in
a
big box
full of hay. Dm is finding in
the hay stack (huge
data) the needle (knowledge).
You don't
have
idea about where the needle
can be found or even you
don't know whether the
needle is
there in
the haystack or not.
Historically,
the notion of finding useful
patterns in data has been
given a variety of
names,
including
data mining, knowledge extraction,
information discovery, information
harvesting, data
archaeology,
and data pattern processing.
The term data mining
has mostly been used
by
stati ticians,
data analysts, and the
management information systems
(MIS) communities. It
has
s
also
gained popularity in the
database field. KDD refers to
the overall process of
discovering
useful knowledge
from data, and data
mining refers to a particular step in
this process. Data
mining is
the application of specific algorithms
for extracting patterns from
data. The additional
steps in
the KDD process, such as
data preparation, data selection,
data cleaning, incorporation
of
appropriate
prior knowledge, and proper
interpretation of the results of mining, is
essential to
ensure
that useful knowledge is derived from
the data. Blind application of
data-mining methods
(rightly
criticized as data dredging in the
statistical literature) can be a
dangerous activity,
easily
leading to the
discovery of meaningless and invalid
patterns.
An important to
note here is the use of term
discovery
rather
than finding. This is so
because you
find
something that you know
you have lost, or you
know that something exist
but not in your
approach so you
search for that and
find. In DM as we are saying
again and again you don't
know
237
what you
are looking for. In other words you
don't know the results, so
the term discovery rather
than
finding is used.
In the
given definition, the 5 key
words are;
Nontrivial
By nontrivial,
we
mean that some search or
inference is involved; that is, it is
not a
straightforward
computation of predefined quantities like
computing the average value of a set
of
numbers.
For example, suppose the
majority of the customers of a
garments shop are men.
If
some women too
buy garments then it's
common and trivial because
women sometimes buy for
their
children and spouse.
Similarly if "Suwaiyan" sale
increases during Eid days,
the sugar, milk
and
date sales also in crease.
The information again is
trivial. If the sale of some
items boosts up,
even when no Eid
was around, in some region of
the country, this is non
-trivial information
Value
The
term value refers to the
importance of discovered hidden patterns to
the user in terms of
its
usability,
validity, benefit and understandability.
Data mining is a way to
intelligently probing
large databases
to find exactly where the value
resides.
Multidimensional
By multidimensional we
mean a database designed as a
multidimensional hypercube with
one
axis per
dimension. In a flat or relational
database, each field in a record
represents a dimension.
In a multidimensional
database, a dimension is a set of
similar entities; for
example, a
multidimensional
sales database might include
the dimensions Product,
Time, and City. Data
mining
Multidimensional databases allows users
to analyze data from many
different dimensions
or angles,
categorize it, and summarize
the relationships
identified.
Unrelated
Humans
often lack the ability to
comprehend and manage the
immense amount of available
and
unrelated data.
Data mining can help us take
very small pieces of data
that are seemingly
unrelated i.e.
no relationship exits, and determine
whether they are correlated and
can tell us
anything that we
need to know".
Business
Knowledge
The domain
business processes must be
known apriority before
applying defaming
techniques.
Since
data mining is an exploratory approach we
can not know what we should
know, until and
unless we
are not well aware of the
activities involved in current business
processes.
People
Human
involvement in the data
mining process is crucial in sense
that value of patterns is
well
known to
the user. Since data
mining focuses on "unknown
unkowns" ,
people factor plays a
key
role in
directing data mining probe in a direction
that ultimately ends in something
that is
previously
unknown, novel, and above all of
value. Thus, Data mining
has proven to be a
238

powerful
tool capable of providing
highly targeted information to
support decision-making and
forecasting for
people like scientists,
physicians, sociologists, the
military and business
etc.
Algorithms
Data
mining consists of algorithms for
extracting useful patterns from
huge data. Their goal is
to
make prediction
or/and give description.
Prediction involves using
some variables to predict
unknown values
(e.g. future values) of other variables
while description focuses on
finding
interpretable
patterns describing the data.
These algorithms can sift through
the data in search of
frequently
occurring patterns, can detect
trends, produce generalizations
about the data, etc.
There
are
different categories of data algorithms
based on their application, approach
etc. Commonly
used
are classification algorithms, clustering algorithms,
rule based algorithms, and
artificial
neural networks
etc.
Statistics
Data
Mining uses statistical
algorithms to discover patterns and
regularities (or "knowledge")
in
data.
For example: classification
and regression trees (CART,
CHAID), rule induction
(AQ,
CN2),
nearest neighbors, clustering
methods, association rules, feature
extraction, data
visualization,
etc.
Data
mining is, in some ways, an
extension of statistics, with a
few artificial intelligence
and
machine
learning twists thrown in.
Like statistics, data mining
is not a business solution, it is
just
a
technology.
Computing
Technology
Data
mining is an inter disciplinary approach
having knowledge from different
fields such as
databases,
statistics, high performance computing,
machine learning, visualization
and
mathematics to
automatically extract concepts, and to
determine interrelations and patterns
of
interest
from large databases.
Why
Data Mining?
HUGE
VOLUME THERE IS
WAY TOO MUCH DATA &
GROWING!
Data
collected much faster than
it can be processed or managed.
NASA Earth Observation
System
(EOS), will alone, collect
15 Peta bytes by 2007
(15,000,000,000,000,000 bytes).
�
Much of
which won't be used -
ever!
�
Much of
which won't be seen -
ever!
�
Why
not?
�
There's so
much volume, usefulness of
some of it will never be
discovered
SOLUTION:
Reduce
the volume and/or raise the
information content by structuring,
querying,
filtering,
summarizing, aggregating,
mining...
Data
Mining is the exploratory data
analysis with litt le or no
human interaction
using
computationally
feasible techniques, i.e.,
the attempt to find
interesting structures/patterns
unknown a
priori
239
The
ability of data mining
techniques to deal with huge
volumes of data is a distinguishing
characteristic.
The data volumes of
organizations/enterprises/businesses are
increasing with a
greater
pace e.g. NASA Earth
Observing System (EOS) generates
more than 100 gigabytes
of
image
data per hour, stored in
eight centers. Data
collected much faster than
it can be processed
or managed.
NASA EOS will alone,
collect 15 Peta bytes by
2007 (15,000,000,000,000,000
bytes).
Plunging in to such a deep
and vast sea of data and
performing analysis is not
possible
through conventional
techniques. So majority of the data
will remain untouched,
unseen, unused
thus
limiting the discovery of useful
patterns. This requires the
availability of tools
and
techniques
that can accommodate the
huge volumes of data and its
complexity. Obviously, data
mining is
the best fit. It works by reducing
the data volume and/or
raise the information
content
user
interest by structuring, querying, filtering,
summarizing, aggregating, mining
etc. By raising
information
content means that the
those patterns are built
and brought to surface that
are
otherwise hidden
and scattered in the data
sea and of user
interest.
Claude
Shannon's info.
theory
More
volume means less
information
Claude
Shannon's theory states that
as the volume increases the
information content
decreases
and
vice versa.
De ci sion (Y/N)
(Machine
Decides)
De ci sion
Support
(Machine
Helps Choose
Rules)
Knowledge
(Machine
Discovers Rules)
Value
of
In forma tion
(Machine
aggregateshi-lights/
/
Data
correlates/summarizes)
Indexed Da ta
(Machine
finds directly w/o
Scan)
Ra w Da
ta
(Machine
Scans)
Volume
of
Data
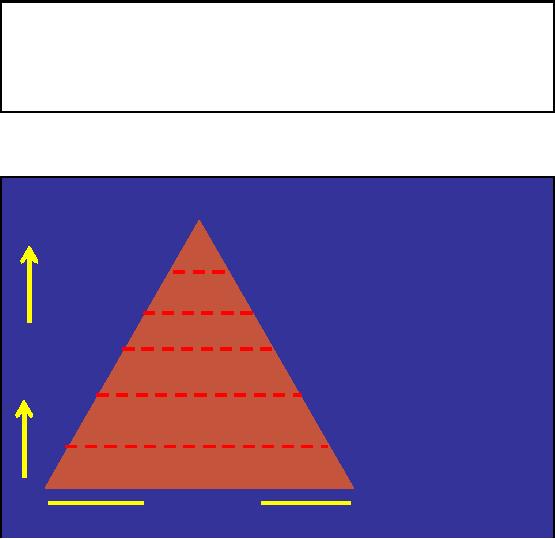
Figure-29.1: Claude
Shannon's info.
theory
240

The Figure
29.1 well illustrates the
Shannon's Information Theory. At the
base lies the raw
data
having maximum
volume. Here the data value,
that increases as we go up (volume
decreases), is
the
minimum. Here exploring data
for useful information needs conventional
data scanning, thus
one is
lost in the deep blue sea,
reaching no-where.
In the
next level is the indexed
data. Data indexing has
greatly reduced the data
volume as
compared to
the data in the lower
level (raw data). Now we
have found short cuts, to
reach
desired points
in the voluminous data sea,
rather than conventional scanning.
The data has more
value
than the data at lower
level.
In the
next level is the
aggregate/summarized data. Here the
data is in a form that can
readily be
used as
information. Thus much compact
volume and greater data
value than the previous
lower
levels.
Next is the
level where the machine
discovers and learns rules.
The rules can easily be
applied to
extract
only desired data, or knowledge
base thus greatly reducing the
data volume as
compared
to other
lower levels.
The
next is the level where
machine supports decision
making process by helping in
selecting
appropriate pre
defined rules. Here d ata
volume is minimal and
similarly higher data value
than
the
lower levels.
The
final top most level is
where the machine itself
makes decisions based on predefined
rules.
Those
most appropriate rules are
selected by machine itself
for making a decision.Here of
course
the
data volume is minimum and
the value of data is thus
maximum.
Why
Data Mining?: Supply &
Demand
Amount of
digital data recording and
storage exploded during the
past decade
BUT
number of
scientists, engineers, and
analysts available to analyze
the data has not
grown
correspondingly.
Another
reason of Data mining is
that the data generation
rate far exceeds the
data capturing and
analysis
rate. In other words, the amount of
digital data storage in
different organizations
world
wide
has greatly increased in the
past few decades. However,
the number of scientists,
engineers
and
analysts for data analysis
has not grown accordingly i.e.
the supply of desired
scientists and
researchers
don't meet their high
demand in high numbers, so
that the huge and
continuously
increasing
data can be consumed or
analyzed. Thus data mining
tools provide a way, enabling
limited
scientists and researchers to
analyze huge amounts of
data.
241

Why Data
Mining?: Bridging the
gap
Requires
solution of fundamentally new problems,
grouped as follows:
1. developing
algorithms and systems to mine large,
massive and high dimensional
data
sets;
2. developing
algorithms and systems to mine new
types of data (images,
music, videos);
3. developing
algorithms, protocols, and
other infrastructure to mine distributed data;
and
4. improving
the ease of use of data
mining systems;
5. developing
appropriate privacy and
security techniques for data
mining.
Data
mining evolved as a mechanism to
cater the limitations of OLTP
systems to deal
massive
data
sets with high dimensionality,
new data types, multiple
heterogeneous data resources
etc.
The conventional
systems couldn't keep pace
with the ever changing
and increasing data
sets.
Data mining
algorithms are built to deal
high dimensionality data, new
data types (images,
video
etc.) ,
complex associations among
data items , distributed data
sources and associated
issues
(security
etc.)
Data Mining is
HOT!
� 10 Hottest
Jobs of year 2025
Time
Magazine, 22 May,
2000
�
10 emergi
ng areas of technology
MIT's
Magazine of Technology Review, Jan/Feb,
2001
The
TIME Magazine May 2000 issue
has given a list of the ten
hottest jobs of year 2025.
Data
miners
and knowledge engineers were at 5h a n d 6h position respectively.
The proposed
t
t
course/Curriculum
will cover Data Mining.
Hence Data mining is a hot
field having wide
market
opportunities.
Similarly,
MIT's Technology Review has
identified 10 emerging areas of
technology that will
soon
have a profound impact on
the economy and how we
live and work. Among
the list of
emerging
technologies that will
change the world, Data
mining is at the 3r d place.
Thus in
view of the above facts, data
miners have a
long career in national as well
a
s
international
market as major companies both
private and government are
quickly adopting the
technology
and many have already
adopted.
242
How
Data Mining is different?
n Knowledge
Discovery
--Overall
process of discovering useful knowledge
n Data Mining
(Knowledge-driven
exploration)
-- Query
formulation problem.
-- Visualize and
understand of a large data
set.
-- Data
growth rate too high to be
handled manually.
n Data
Warehouses (Data-driven
exploration):
-- Querying
summaries of transactions, etc.
Decision
support
n Traditional
Database (Transactions
):
-- Querying data
in well-defined processes. Reliable
storage
Conventional
data processing systems or
online transaction processing
systems (OLTP) lie at
the
bottom level.
These systems have well
defined queries and no any
sort of knowledge discovery is
performed.
OLTP systems are meant to
support day to day
transactions and do not
support
decision making
in any way. We can better
understand with the analogy
that when you travel
from
your home to university you
may follow a same route very
often. While on the way you
will
see
same trees, same signals
and same buildings every
day provided you follow the
same route. It
is not possible
that each and every
day you see different buildings,
trees than the previous
day.
Similar is
the case for OLTP
systems where you have well
defined queries by running
which you
know what
sort of results you can get.
Nothing new or no discoveries
are here.
Data
Mining provides a global
macroscopic view or aerial view of
your data. You can
easily see
what you could not
see at microscopic level.
But before applying mining
algorithms data must be
brought in a
form so that the knowledge exploration
from huge, heterogeneous and
multi source
data
can efficiently and
effectively be performed. Thus DWH is the
process of bringing input
data
in a form
that can readily be used by
data mining techniques to
find hidden patterns. Both
terns
KDD
and DM are sometimes used to
refer to the same thing but
K D refers to the overall
D
process
from data extraction from
legacy source systems, data
preprocessing, DWH
building,
data
mining and finally the
output generation. So KDD is a mega
process having sub
processes
like
DWH and DM being its
constituent parts.
How
Data Mining is different...
Data
Mining Vs.
Statistics
�
Formal
statistical inference is assumption
driven i.e. a hypothesis is
formed and validated
against
the data.
�
Data
mining is discovery driven
i.e. patterns and hypothesis
are automatically ext
racted
from
data.
�
Said
another way, data mining is
knowledge driven, while statistics is
human driven.
Although both of
the two are for
data analysis and none is
good or bad, some of the
difference
between
statistics and Data mining
are;
243
Statistic s
assumption driven. A hypothesis is
formed using the historical
data and is then
i
validated
against current known data.
If true the hypothesis
becomes a model else the
process is
repeated
with different parameters.
DM, on the other hand, is
discovery driven i.e. based on
the
data
hypothesis is automatically extracted
from the data. The
purpose is to find patterns
which are
implicit
and hidden in the data sea
otherwise. Thus data mining is knowledge
driven while
statistics is
human driven.
Data Mining
Vs. Statistics
�
Both
resemble in exploratory data
analysis, but statistics focuses on
data sets far smaller
than
used by data mining
researchers.
�
Statistics is
useful for verifying relationships
among few parameters when
the
relationships
are linear.
�
Data
mning builds much complex, predictive,
nonlinear models which are
used for
i
predicting
behavior impacted by many
factors.
One
difference is on the type of
data. While statistician
traditionally work with
smaller and first
hand
data" that has been
collected or produced to check
specific hypotheses, data
miners work
with
huge and second hand
data" often assembled from
different sources. The idea
is to find
interesting
facts and potentially useful knowledge hidden in
the data and often
unrelated to the
primary
purpose why the data
have been collected.
Statistics
provides a language and framework
for quantifying the
uncertainty that results
when
one
tries to infer general
patterns from a particular sample of an
overall population. The
concern
arose
because if one searches long
enough in any data set
(even randomly generated
data), one
can
find patterns that appear to
be statistically significant but, in
fact, are not.
Statistics is
useful only for data sets
with limited parameters
(dimensions) and
simple
relationships
(linear). Statistical methods
fail when the data
dimensionality is greater and
the
relationships
among different parameters
are complex. Data mining
proves to be viable solution
in such
situations.
Thus,
data mining is a legitimateflactontVshSttocuilids
mx decseaseng capability to
incarnate in them
ivi y t a b
k ned oin lr havi
In
ati
intricate data
sets with greater dimensionality
and complex associations
that are non linear.
The
models
are used to predict behaviors impacted by
different combinations of
factors.Knowledge
40
extraction
using statistics
30
20
10
0
1.6
1.7
1.8
1.85
1.9
1.95
2
2.9
3
3.3
4.2
4.4
5
6
Inflation
(%)
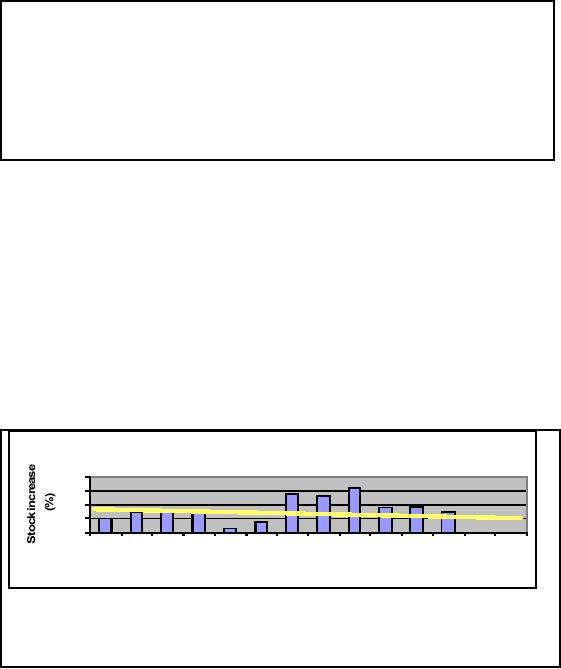
Q: What
will be the stock increase
when inflation is 6%?
A: Model non
-linear relationship using a line
y = mx
+ c. Hence
answer is 13%
Figure-29.2:
Knowledge extraction using
statistics
244
What
statistics can offer for
knowledge discovery? Consider
the histogram in Figure 29.2.
It
shows
the relationship between
%inflation and %stock
increase. What if we want to know
the
value of
%stock increase at 6% inflation? W
can use linear regression as
shown by yellow line in
the
figure. The line acts as a
conducting wire, balanced
between magnets (bars). Thus
regression
here is
like balancing of a wire, so that
the final position of the
line is as shown in Figure
29.2.
Thus we use
curve fitting with linear
regression and the line
equatio n y=mx+c
to
calculate the
value at 6%
inflation. Here m is the slope x is
known 6% and c is the
intercept.
Realistically
only two variables here,
however, in real life many
variable may be more than
50. In
such
situations linear regression, the
statistical methods
fail.
Failure of
regression models
y = -0.0127x 6 + 1.5029x5 -
63.627x 4
+
1190.3x3
- 9725.3x
2 + 31897x -
29263
70000
60000
50000
40000
30000
20000
10000
0
0
5
10
15
20
25
30
35
-10000
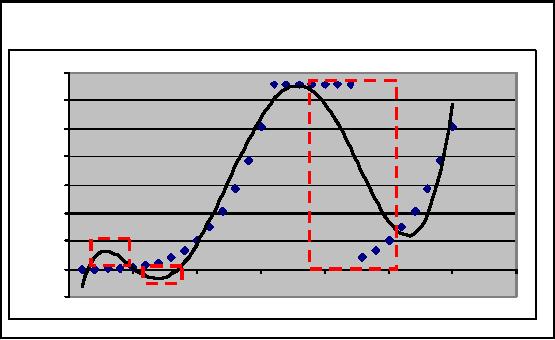
Figure-29.3:
Failure of regression
models
To better
understand the limitation of
regression, consider a real life
example in Figure 29.3.
Although l
two variables here too, but
the relationship is not that much
simple. In real life
the
association
between variables is not that
much simple rather complex
as shown by the equation
in
Figure -29.3.
Here dotted line is the
actual data. The non
linearity of the association
leads to the
dotted
line structure having peaks
and falls. Here we can't use
linear regression like we
did in our
previous
example. Here we do a polynomial curve
fitting like degree 6 curve
fitting shown by
regular line in
the figure. The red dotted
boxes show the di fference
between the actual and
the
curve
fitting. We can seen the
difference is initially is less
than what we can see in the
next red
doted box in
the middle. Thus the crux is
that regression just failed
even for two variables
with
complex
associations. How can it be
applied to real life data
having 20, 25 or even 50
attributes?
245
Data Mining
is...
�
Decision
Trees
�
Neural
Networks
�
Rule
Induction
�
Clustering
�
Genetic
Algorithms
Now
lets discuss something about
what is included in DM and what is not. First we
will discuss
what DM
is.
Decision
Trees (DT): Decision trees
consist of dividing a given
data set into groups
based on
some
criteria or rule. The final
structure looks like an
inverted tree, hence the
technique called
DT.
Suppose a table having a number of
records. The tree
construction process will group
most
related
records or tuples in the
same group. Decision at each node is
taken based on some rule,
if
this
then this else this.
Rules are not known a priori
and are digged out of the
training data set.
Clustering:
It is
one of the most important Dm
techniques; we will discuss it in detail
in coming
lectures. As a
brief for understanding it
involes the grouping of data
items without taking
any
human
parametric input. We don't know
the number of clusters and
their properties a priori.
Two
main
types are one way clustering
and two way clustering.
One way clustering is when
only data
records
(rows) are used. Two
way clustering is when all
the rows and columns
are being used for
clustering
purpose.
Genetic
Algorithms: These
are based on the principle
survival of the fittest. In
these techniques,
a model is
formed to solve problems
having multiple options and
many values. Briefly,
these
techniques
are used to select the
optimal solution out of a number of possible
solutions. However,
are
not much robust as can not
perform well in the presence
of noise.
246
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orr’s Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling