 |
Lecture-27
Need
for Speed: Special Indexing
Techniques
Without
indexes, th e DBMS may be
forced to conduct a full
table scan (reading every
row in the
table) to locate
the desired data, which
can be a lengthy and inefficient
process. However,
creating
indexes requires careful
consideration. Although indexes
can be quite useful for
speeding
data
retrieval, they can slow
performance of database writes. This
slowdown occurs because
a
change to an
indexed column actually requires
two database writes -one to
reflect a change in
the
table
and one to reflect a corresponding
change in the index. Thus,
if the activities associated
with
a table
are primarily write -intensive, it is
important to make judicious use of
indexes on the
relevant
tables. Indexes also require
a certain amount of disk
space, which must be
considered
when
allocating resources to the
database.
Before
looking at your indexing
options, we must first
discuss the two ways to
access data: non -
keyed
access and keyed access.
Non-keyed access uses no
index. Each record of the
database is
accessed
sequentially, beginning with the
first record, then second,
third and so on. This
access is
good when you wish to
access a large portion of the
database (greater than 85%).
Keyed access
provides direct
addressing of records. A unique number or
character(s) is used to locate
and
access
records. In this case, when
specified records are required
(say, record 120, 130, 200
and
500), indexing is
much more efficient than
reading all the records in
between.
Special
Index Structures
�
Inverted
index
�
Bit
map index
�
Cluster
index
�
Join
indexes
Table-27.1:
Special Index
Structures
Inverted
index: Concept
An inverted
index is an optimized structure that is
built primarily for
retrieval, with update
being
only a
secondary consideration. The
basic structure inverts
the
text so that instead of the
view
obtained
from scanning documents where a
document is found and then
its terms are seen
(think
of a list of
documents each pointing to a list of
terms it contains), an index is built
that maps
terms to
documents (pretty much like
the index found in the
back of a book that maps
terms to
page
numbers). Instead of listing
each document
once (and
each term repeated for
each document
that
contains the term), an inverted index
lists each term in the
collection only once and
then
219
shows a list of
all the documents that
contain the given term.
Each document identifier is
repeated
for
each term that is found in
the document.
Within
the search engine domain, data
are searched far more
frequently than they are
updated.
This is typical
for a data wa rehouse, where
updates hardly take place.
Given this situation a
data
structure
called an inverted index
commonly
used by search engines is
also applicable for the
data
warehouse
environment.
An inverted
index is able to do many accesses in
O
(1) time at
the price of significantly
longer
time to do an
update, in the worst case
O(n).
Index
construction time is longer as well, but
query
time is generally faster
than with a B-tree i.e.
O(log n). Since index construction is an
off -line
activity, so it
is an appropriate tradeoff i.e.
shorter query times at the
expense of lengthier index
construction
times.
Finally,
inverted index storage structures
can exceed the storage
demands of the
document
collection itself.
However, the inverted index
can be compressed for many
systems, to around
10% of
the original document collection.
Given the alternative (of 26 minute
searches), search
engine
developers are happy to trade index
construction time and storage
for query efficiency.
Same is
also true for the DSS
environment.
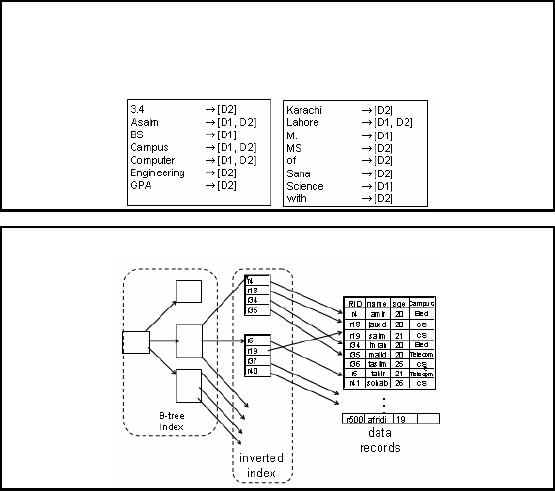
Inverted
Index: Example-1
D1: M.
Asalm BS Computer Science Lahore
Campus
D2:
Sana Aslam of Lahore MS Computer
Engineering with GPA 3.4 Karachi
Campus
Inverted index
for the documents D1 and D2
is as follows:
Inverted
Index: Example-2
220
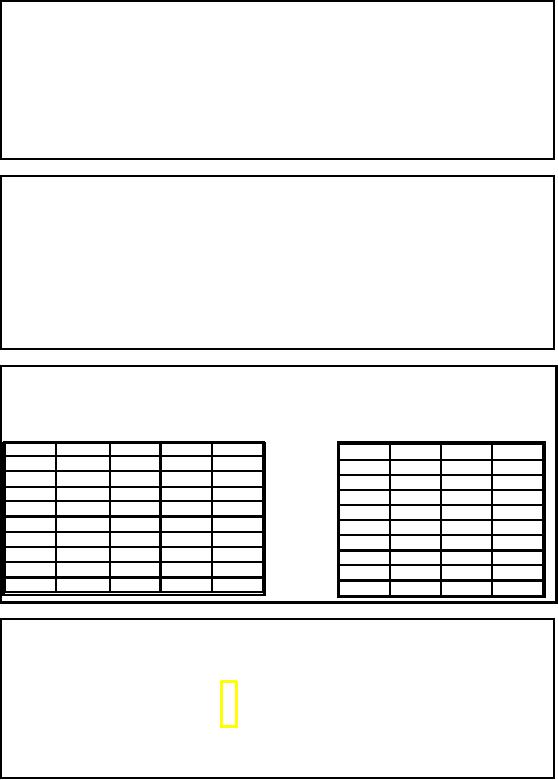
Figure-27.1:
Inverted Index:
Example-2
Inverted
Index: Query
�
Query:
o Get
students with age = 20 and
tech = "telecom"
�
List
for age = 20: r4, r18, r34,
r35
�
List
for tech = "telecom": r5,
r35
�
Answer is
intersection: r35
Bitmap
Indexes: Concept
�
Index on a
particular column
�
Index
consists of a number of bit vectors or
bitmaps
�
Each
value in the indexed column
has a corresponding bit
vector (bitmaps)
�
The length of
the bit vector is the
number of records in the
base table
�
The
ith bit is
set to 1 if the ith row of
the base table has
the value for the
indexed column
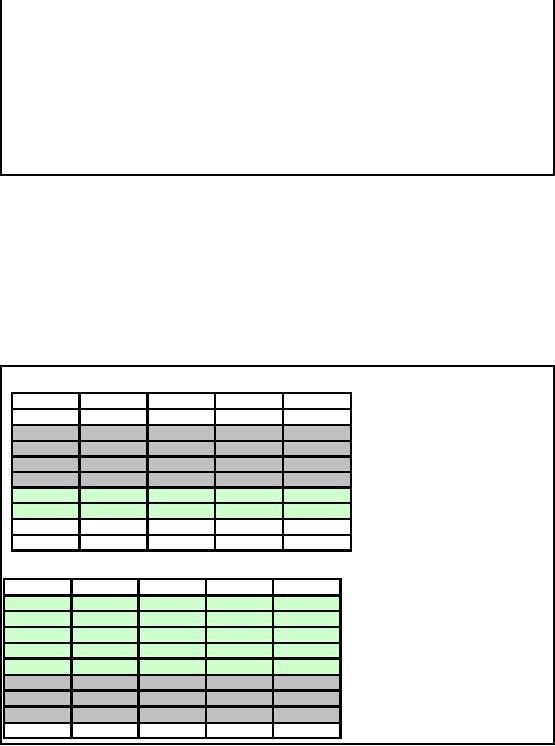
Bitmap
Indexes: Example
�
The index
consists of bitmaps, with a column
for each unique
value:
Index on
City (larger table):
Index on Tech
(smaller table):
SID
Islamabad
Lahore
Karachi
Peshawar
SID
CS
Elect
Telecom
1
0
1
0
0
1
1
0
0
2
1
0
0
0
2
0
1
0
3
0
1
0
0
3
0
1
0
4
0
0
0
1
4
1
0
0
5
0
0
1
0
5
0
0
1
6
0
0
1
0
6
0
1
0
7
0
0
0
1
7
0
0
1
8
0
0
0
1
8
1
0
0
9
0
1
0
0
9
1
0
0
Table-27.2:
Bitmap Indexes:
Example
Bitmap
Index: Query
�
Query:
� Get
students with age = 20 and
campus = "Lahore"
�
List for
age = 20:
1101100000
�
List
for campus = "Lahore":
1010000001
�
Answer is AND
:
1000000000
�
Good if domain
cardinality is small
�
Bit
vectors can be
compressed
� Run length
encoding
221

Bitmap
Index: Run Length
Encoding
Basic
Concept
1111000011110000001111100000011111
INPUT
Case-1
14#04#14#06#15#06#15
OUTPUT
1010101010101010101010101010101010
INPUT
Case-2
11#01#11#01#11#01#11#01#...
OUTPUT
11111111111111110000000000000000
INPUT
117#017
OUTPUT
Case-3
Bitmap
Index: More Queries
�
Allow
the use of efficient bit
operations to answer queries,
such as:
"Which
students from Lahore are enrolled in
`CS'?"
o
Perform a
bit -wise AND of two
bitmaps: answer s1 and s9
"How
many students are enrolled in
`CS'?"
o
Count 1's in
the degree bitmap
vector
Answer is
4
Bitmaps
are not good for high- cardinality
textual columns that have
numerous values, such
as
names or
descriptions, because a new column is
created in the index for
every possible value.
With high -cardinality
data and a large number of
rows, each bitmap index becomes
enormous and
takes a
long time to process durin g
indexing and retrievals.
Bitmap
Index: Adv.
�
Very
low storage space.
�
Reduction in
I/O, just using
index.
�
Counts &
Joins
�
Low
level bit operations.
An obvious
advantage of this technique is
the potential for dramatic
reductions in storage
overhead.
Consider a table with a
million rows and four
distinct values with column
header of 4
bytes resulting
in 4 MB. A bitmap indicating which of
these rows are for these
values requires
about
500KB.
More
importantly, the reduction in the
size of index "entries" means that
the index can
sometimes
be processed
with no I/O and, more often,
with substantially less I/O
than would otherwise be
222

required. In addition,
many index-only queries
(queries whose responses are
derivable through
index scans
without searching t he database)
can benefit
considerably.
Database
retrievals using a bitmap index can be
more flexible and powerful
than a B-tree in that
a
bitmap
can quickly obtain a count by inspecting
only the index, without
retrieving the actual
data.
Bitmap indexing
can also use multiple
columns in combination for a given
retrieval.
Finally, you
can use low-level Boolean
logic operations at the bit
level to perform
predicate
evaluation at
increased machine speeds. Of
course, the combination of these
factors can resu lt
in
better query
performance.
Bitmap
Index: Performance
Guidance
Bitmapped
indexes can provide very
impressive performance speedups; execution
times of
certain
queries may improve by several
orders of magnitude. The
queries that benefit the
most
from
bitmapped indexes have the
following characteristics:
�
The
WHERE-clause contains multiple
tests on low-cardinality columns
�
The
individual tests on these
low-cardinality columns select a large
number of rows
�
The
bitmapped indexes have been
created on some or all of
these low-cardinality
columns
�
The
tables being queried contain
many rows
A significant
advantage of bitmapped indexes is
that multiple bitmapped
indexes can be used
to
evaluate the
conditions on a single table. Thus, bitmapped indexes
a e very appropriate
for
r
complex ad-hoc
queries that contain lengthy
WHERE-clauses. Performance,
storage
requirements,
and maintainability should be considered
when evaluating an indexing
scheme.
Bitmap
Index: Dis. Adv.
�
Locking of
many rows
�
Low
cardinality
�
Keyword
parsing
�
Difficult to
maintain - need reorganization when relation
sizes change (new
bitmaps)
Row
locking: A potential
drawback of bitmaps involves locking.
Because a page in a bitmap
contains
references to so many rows,
changes to a single row
inhibit concurrent access
for all
other referenced
rows in the index on that
page.
Low
cardinality: Bitmap indexes
create tables that contain a
cell for each row times
each possible
value (the
product of the number of rows times the
number of unique values). Therefore, a
bitmap
is practical
only for low- cardinality
columns that divide the
data into a small number
of
categories,
such as "M/F", "T/F", or
"Y/N" values.
Keyword
parsing: Bitmap indexes
can parse multiple values in a column
into separate
keywords.
For
example, the title "Marry
had a little lamb" could be
retrieved by entering the word
"Marry"
or "lamb" or a
combination. Although this keyword
parsing and lookup capability is
extremely
223
useful,
textual fields tend to
contain high -cardinality
data (a large number of values)
and therefore
are not a good
choice for bitmap
indexes.
Cluster
Index: Concept
�
A Cluster index
defines the sort order on
the base table.
�
Ordering
may be strictly enforced (guaranteed) or
opportunistically maintained.
�
At most
one cluster index defined
per table.
�
Cluster index
may include one or multiple
columns.
�
Reduced
I/O.
The
big advantage of a cluster index is
that all the rows with
the same cluster index value
will be
placed
into adjacent locations in a
small number of data
blocks.
In this
example, all accounts for a
specific customer will be clustered
into adjacent locations
to
increase
locality of reference by customer_id.
Cluster indexing
allows significant reduction in I/Os when accessing
base table via index
because
rows with
the same index value will be
stored into the same
blocks. This is a big win
for indexed
access
for query execution against a
single table as well as
nested loop joins using
indexed
access.
Cluster indexing has the
effect of transforming a random I/O
workload into a
sequential
I/O
workload when accessing through the
cluster index.
Cluster
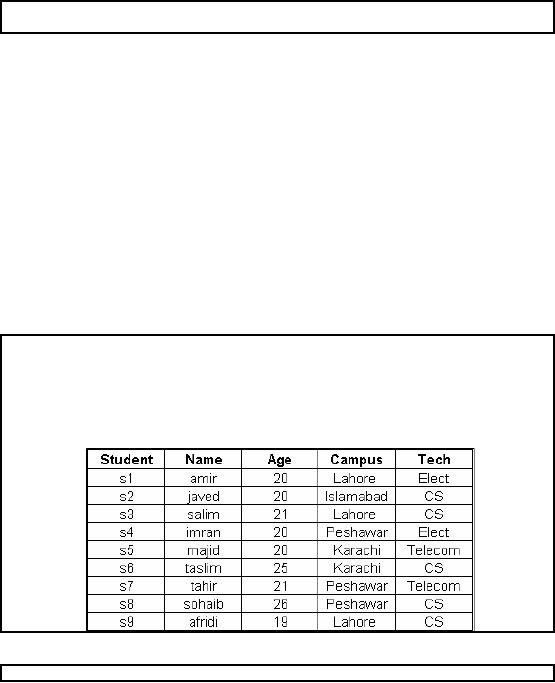
Index: Example
Student
Name
Age
Campus
Tech
s9
afridi
19
Lahore
CS
s1
amir
20
Lahore
Elect
s2
javed
20
Islamabad
CS
s4
imran
20
Peshawar
Elect
Cluster
indexing on AGE
s5
majid
20
Karachi
Telecom
s3
salim
21
Lahore
CS
s7
tahir
21
Peshawar
Telecom
s6
taslim
25
Karachi
CS
s8
sohaib
26
Peshawar
CS
One indexing
column at a time
Student
Name
Age
Campus
Tech
s9
afridi
19
Lahore
CS
s2
javed
20
Islamabad
CS
s3
salim
21
Lahore
CS
Cluster
indexing on TECH
s6
taslim
25
Karachi
CS
s8
sohaib
26
Peshawar
CS
s1
amir
20
Lahore
Elect
s4
imran
20
Peshawar
Elect
s5
majid
20
Karachi
Telecom
s7
tahir
21
Peshawar
Telecom
Table-27.3:
Cluster Index: Example
224
Cluster
Index: Issues
�
Works
well when a single index can
be used for the majority of
table accesses.
�
Selectivity
requirements for making use
of a cluster index are much
less stringent than
for
a non -clustered
index.
o Typically by an
order of magnitude, depending on row
width.
�
High
maintenance cost to keep
sorted order or frequent reorganizations
to recover
clustering
factor.
�
Optimizer must
keep track of clustering
factor (which can degrade
over time) to
determine
optimal execution plan
Significant
performance advantage for query
execution, but beware of the overhea d of
index
maintenance (and
reorganization costs!), at best O (n log
n).
Query plans
will change (or should
change) over time where updates
are occurring because
degradation of
clustering (e.g., adjacency)
will take place over time
until a reorganization is
performed. Note
that this effect assumes
that clustering index does not "force"
sorted order, but
rather that
sorted order is achieved with
initial index build and
periodic reorganization. It is
also
possible to
"force" sorted order at a
higher cost upon insert and
update operations into the
data
warehouse.
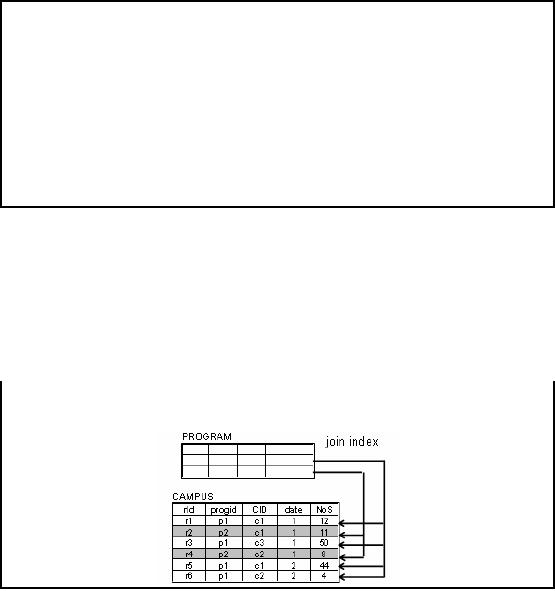
Join
Index: Example
The rows of
the table consist entirely of
such references, which are
the RIDs of the relevant
rows.
Figure-27.2:
Join Index:
Example
225
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orr’s Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling