 |

Lecture-17
Issues of
ETL
Why
ETL Issues?
Data
from different source
systems will be different,
poorly documented and dirty.
Lot of analysis
required.
Easy to
collate addresses and names?
Not really. No address or name
standards.
Use software
for standardization. Very
expensive, as any "standards"
vary from country to
country, not large
enough market.
It is very
difficult to extract the
data from different source
systems, because by definition
they are
heterogeneous,
and as a consequence, there
are multiple representations of
the same data,
have
inconsistent
data formats, have very poor
documentation and have dirty
data etc. Therefore,
you
have to figure
different ways of solving
this problem, requiring lot of
analysis.
Consider
the deceptively simple task of
automating the collating of addresses
and names from
different
operational databases. You can't predict
or legislate format or content,
therefore, there
are no
address standards, and there
are no standard address and
name cleaning software.
There is
software for certain geographies, but
the addresses and names in
US will be completely
different
from that in Austria or Brazil. Every
country finds a way of writing
the addresses
differently,
that is always a big problem.
Hence automation does not solve
the problem, and also
has a
high price tag in case of 1st generation ETL tools
($200K-$400K range).
Why
ETL Issues?
Things
would have been simpler in
the presence of operational systems, but
that is not always
the
case
Manual data
collection and entry. Nothing
wrong with that, but
potential to introduces lots of
problems.
Data is
never perfect. The cost of
perfection, extremely high vs. its
value.
Most
organizations have ERP systems
(which are basically operational
systems) from where
they
load their DWH.
However, this is not a rule,
but used in an environment where
transaction
processing
systems are in place, and
the data is generated in real
time.
However, in
the case of a country -wide
census, there are no source
systems, so data is being
collected
directly and manually. People go
form door to door and
get forms filled,
subsequently
the
data in its most raw
form is manually entered into
the database. There is
nothing wrong with
that,
the problem being human
involvement in data recording and
storage is very expensive,
time
consuming
and prone to errors. There have to be
control and processes to colle ct as
clean a data
as
possible.
128

People
have a utopian view that
they will collect perfect data.
This is wrong. The cost
of
collecting
perfect data far exceeds
its value . Therefore, the
objective should be to get as
clean
data as
can be based on the given
constraints.
"Some"
Issues
�
Usually, if not
always underestimated
�
Diversity in
source systems and
platforms
�
Inconsistent
data representations
�
Complexity of
transformations
�
Rigidity
and unavailability of legacy
systems
�
Volume of
legacy data
�
Web
scrapping
ETL is
something which is usually
always underestimated; consequently
there are many
many
issues.
There can be an entire course on
ETL. Since this course is
not only about ETL,
therefore,
we will
limit our self to discussing
only some of the issues. We
will now discuss some of
the
more
important issues one
-by-one.
Complexity
of problem/work underestimated
�
Work
seems to be deceptively simple.
�
People
start manually building the
DWH.
�
Programmers
underestimate the
task.
�
Impressions
could be deceiving.
�
Traditional
DBMS rules and concepts
break down for very large
heterogeneous
historical
databases.
At first
glance, when data is moved
from the legacy environment
to the data warehouse
environment, it
appears there is nothing more
going on than s imple
extraction of data from
one
place to
the next. Because of the
deceptive simplicity, many organizations
start to build their
data
warehouse
manually. The programmer looks at the
movement of data from the
old operational
environment to
the new data warehouse
environment and declares "I
can do that!" With
pencil
and
writing pad in hand the
programmer anxiously jumps into the
creation of code in the
first
three
minutes of the design and
development of the data
warehouse.
However,
first impressions can be deceiving - in
this case very deceiving.
What at first appears
to be nothing
more than the movement of
data from one place to
another quickly turns into a
large
and
complex task, actually a
nightmare. The scope of the
problem being far larger and far
more
complex
than the programmer had ever
imagined.
129
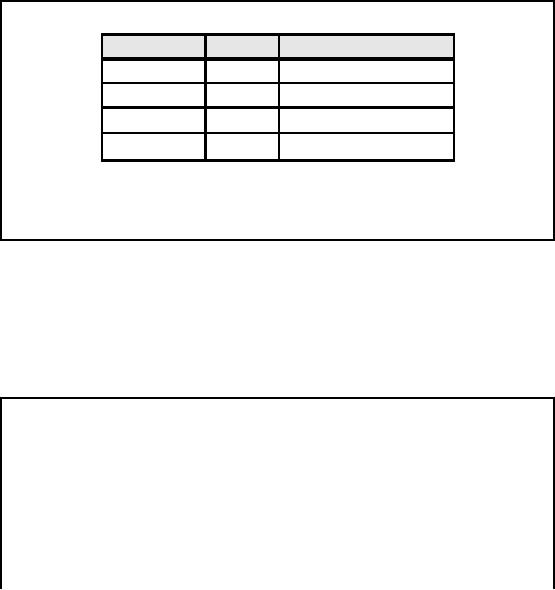
Diversity
in source systems and
platforms
Platform
OS
DBMS
MIS/ERP
Main
Frame
VMS
Oracle
SAP
Mini
Computer
Unix
Informix
PeopleSoft
Desktop
Win
NT
Access
JD
Edwards
DOS
Text
file
Dozens of
source systems across
organizations
Numerous
source systems within an
organization
Need specialist
for each
Table-17.1:
Diversity in source systems
and platforms
There
are literally more than a
dozen different source
system technologies in use in
the market
today.
Example of the kind of
source system technologies
that you often see are
shown in Table
17.1.
The team doing ETL
processing in any given organization
probably has to understand
at
least 6 of
them. You will be surprised
to find big banks and
telecommunication companies
that
have
every single one of these
technologies; in a single company. It is a nightmare
to understand
them.
The only viable solution is to have a
technical expert that knows
how to get data
from
every single
one of these formats. In
short it's a
nightmare.
Same
data, different
representation
Date
value representations
Examples:
970314
1997-03-14
03/14/1997
14-MAR-1997
March 14
1997
2450521.5
(Julian date format)
Gender
value representations
Examples:
- Male/Female -
M/F
-
0/1
-
PM/PF
There
are 127 different ways to spell AT&T;
there are 1000 ways to spell
duPont. How many
ways
are there to represent date?
What is the Julian date
format? All of these
questions and many
more are at
the core of inconsistent
data representation. Don't be
surprised to find source
system
with Julian
date format or dates stored
as text strings.
Consider
the case of gender
representation. You might
think it is just male and
female. W rong.
It's not
just male and female, it
also includes unknown,
because for some people you
don't have
their
gender data. If this was
not sufficient, there is another twist to
the gender i.e. instead of
M
and F, you
come across PM and PF.
What is this? This is probable
male and probable female
i.e.
based on
the name the gender
has been guessed. For
example, if the name is
Mussarat it is
probable female.
It is not for sure, but we
think it is. If it's Riffat,
it is probable male.
130

So you get
all these weird and
strange representations in operational
data, while in a DWH
there
has to be
only ONE and consistent
representation. You just
can't dump all the operational
data
independent of
which source system it came
from that has a different
data representation.
Remember in
the data model you should have non
-overlapping consistent domains
for every
attribute.
Multiple
sources for same data
element
Need to rank
source systems on a per data
element basis.
Take
data element from source
system with highest rank wh
ere element exists.
"Guessing"
gender from name
Something is
better than nothing?
Must
sometimes establish "group
ranking" rules to maintain data
integrity.
First, middle
and family name from
two systems of different
rank. People using middle
name as
first
name.
This
means you need to establish ranking in
the source system on per
element (attribute) basis.
Ranking is all
about selecting the "right"
source system. Rank
establishment has to be based
on
which
source system is known to
have the cleanest data
for a particular attribute. Obviously
you
take
the data element from
the source system with
the highest rank where the
element exists.
However, you
have to be clever about how
you use the rank.
For
example, consider the case of
the gender data coming from
two different source systems
A
and B. It
may be the case that
the highest quality data is
from source system A, where
the boxes
for
the gender were checked by
the customers themselves.
But what if someone did not
check the
gender
box? Then you go on to the
next cleanest source system
i.e. B, where the gender
was
guessed
based on the name.
Obviously
the quality of available
data for source system B is
not as good as that of source
system A, but
since you do not have data
for this particular indiv
idual in source systems A, so
it
is better to
have something then nothing.
This is arguable i.e. maybe
it is better to have nothing
than to
have dirty data. The
point is if you have some
level of confidence in the data you
should
take it.
Typically it is a good idea to remember
from where you took the data, so you
can use this
information
from an analytic point of
view e.g. where you get
clean data etc.
Consider the
case of name i.e. first
name, middle name and
family name and two
source systems
i.e. C and D.
Assume that source system C
has higher quality data
entry, and management
and
processes
and controls as compared to D. Also
assume that source system C
does not have the
middle
name, while source system D
has the complete name.
Since C has a higher
precedence, so
you take
the first name and
the family name from it. But
you really would like to have
the middle
name so you
take it from source system
D. This turns out to be a big problem,
because people
sometimes
use their middle name as
their first name e.g.
Imran
Baqai instead of
Shezad
Imran
Baqai.
131

Complexity
of required transformations
Simple
one-to-one scalar
transformations
- 0/1 ?
M/F
One-to-many
element transformations
- 4 x 20 address
field ? House/Flat, Road/Street,
Area/Sector, City.
Many-to-many
element transformations
- House-holding
(who live together) and
individualization (who are
same) and same
lands.
There is a
spectrum of simple all the
way up to very complex transformations
that you can
implement.
And you probably end up with
many in most DWH
deployments. The
transformations
are typically divided into
three categories as
follows:
�
Simple
one -to-one scalar
transformations.
�
One -to-many
element transformations.
�
Complex
many-to-many element
transformations.
Simple scalar
transformation is a one-t o-one mapping
from one set of values to
another set of
values using
straightforward rules. For
example, if 0/1 corresponds to male/female in
one source
system,
then the gender is stored as
male/female in the
DW.
A one-to-many transformation
is more complex than scalar
transformation. As a data element
form
the source system results in
several columns in the DW. Consider
the 6� 30 address
field (6
lines of 30
characters each), the
requirement is to parse it into
street address lines 1 and
2, city,
sate
and zip code by applying a parsing
algorithm.
The
most complex is many-to-many
element transformations. Good examples
are house holding
and
individualization. This is achieved by
using candidate keys and
fuzzy matching to determine
which
individuals are the same
individuals, and which
individuals go in the same
household and
so on.
This is a very complex transformation
and will be discussed in BSN
lecture.
Rigidity
and unavailability of legacy
systems
�
Very
difficult to add logic to or
increase performance of legacy
systems.
�
Utilization of
expensive legacy systems is
optimized.
�
Therefore,
want to off-load transformation cycles to
open systems environment.
�
This often
requires new skill
sets.
�
Need
efficient and easy way to
deal with incompatible mainframe data
formats.
Legacy
systems typically mean mainframe type
systems that are very
expensive to buy and
operate. We
are talking about CPU
cycles as well as storage, but
mainly computing CPU
cycles.
The mainframe
machines are usually 110%
utilized in most businesses. The
reason being,
businesses
want the "most bang for
the buck", so they keep on
putting more and more load on
the
machines.
132

Consider an
expensive ERP system, when is
the system available for
the processing of DWH
transformations?
Probably never, as the system
utilization has already been
maxed up. So the
big
question is
where to do the transformations? Where do
the CPU cycles come from?
And when the
legacy
data is in a mainframe environment,
typically the cost of transformation is
very high
because of
scarcity and cost of legacy
cycles. But you don't want the
cost of constructing
the
DWH to
exceed the value of the
DWH. So you need to think of
ways to move the cycles to
more
cost
efficient environments.
Therefore, in
case of legacy environment, generally you
want to off -load the
transformation
cycles to
open systems environment. Open
system i.e. Intel chipset,
operating systems like
Unix
and NT
etc. as it results in a much
more cost effective approach
than doing things in a
mainframe
type of
environment. However, this may
sometimes be problematic for
some organizations
requiring
certain new skill sets.
For example the IT
department of a bank may
have only used a
mainframe
for day-to-day operations, and
moving on to open systems
may be painful for
them
due to
the learning curve
etc.
It is NOT simply
moving the data to open
systems; there are lots of
issues due to legacy
systems,
simple as
well as complex. For
example, in the mainframe environment you have
EBCDIC
character
representation and in open
systems it is always ASCII, so you
have to do the
conversion. In mainframe
environment there is packed
decimal encoding, zone
decimal and weird
date formats
that are not understandable in
the open systems
environment. So you have to have
utilities for
doing the conversion and so on before
the required transformation takes
place.
Volume of
legacy data
�
Talking
about not weekly data, but
data spread over
years.
�
Historical data
on tapes that are serial
and very slow to mount
etc.
�
Need
lots of processing and I/O
to effectively handle large data
volumes.
�
Need
efficient interconnect bandwidth to
transfer large amounts of
data from legacy
sources to
DWH.
The
volume of legacy data is typically
very large. It is not just
going back and getting tape
for one
month of billing
data, but getting billing data
for as much as one could get
hold of (say), three
years of
billing data. Imagine the
volume of work, lots of
processing and I/Os especially
when the
data is on
tapes. This w ould involve
tape mounts, and manual
tape mounts is painstakingly slow.
It takes
forever to mount hundreds
and hundreds of tapes. The
IT people will hate you
after you
are through
with tape mounts and
data retrieval.
Assuming
transformation takes place on the
mainframe; the next issue is to
move large volumes
of data
from the mainframe into the
DWH requiring network bandwidth. The
data may have to be
moved
across the LAN, and
maybe even across the WAN
which is more painful.
Therefore, the
DWH
architects need to pay a lot
of attention to capacity planning
issues of the DWH i.e.
how to
size
the DWH, how much is it
going to cost to extract all
the data, prepare the
data, and move
the
data
from a network capacity
planning perspective. Ensure
that from a capacity
planning point of
view
all these aspects are
considered.
133

Web
scrapping
�
Lot of
data in a web page, but is
mixed with a lot of
"junk".
�
Problems:
� Limited
query interfaces
� Fill in
forms
�
"Free text"
fields
� E.g.
addresses
�
Inconsistent
output
� i.e., html
tags which mark interesting
fields might be different on
different
pages.
�
Rapid change
without notice.
During
the last decade the web
has grown from a curiosity
to a required information
repository.
From news
headlines and stories,
financial data and reports,
entertainment events,
online
shopping
and business to business
commerce, the Web has it
all. The promise of the web
is that
all of
this information will be
easily maintained, monitored, queried,
and browsed. Some of
the
promise has
already been realized but much remains to
be done. Web browsers (such
as Internet
Explorer
and Netscape) have been
very successful at displaying web
-based information on a
computer
monitor.
However,
there remains a divide
between content presented on
web pages and the
ability to
extract
that content and make it
actionable. What companies
and individuals need is a
method to
extract or mine
only that data or content in
which they are interested.
Furthermore, they need
to
be able to
take that mined content, apply
different kinds of data
processing, and make it
available
for
use in different applications,
and have it delivered to a
database, email, spreadsheet,
mobile
phone, or
whatever delivery destination device is
available.
Web
scrapping is a process of applying
screen scrapping techniques to
the web. There are
several
web
scrapping products in the
market and target business
users who want to creatively
use the
data,
not write complex scripts.
Some of the uses of
scrapping are:
�
Building
contact lists
�
Extracting
product catalogs
�
Aggregating real
-estate info
�
Automating
search Ad listings
�
Clipping
news articles etc.
134

Beware of
data quality (or
lack of it)
�
Data
quality is always worse than
expected.
�
Will
have a couple of lectures on
data quality and its
management.
�
It is not a
matter of few hundred
rows.
�
Data
recorded for running
operations is not usually good enough for
decision support.
�
Correct totals
don't guarantee data
quality.
�
Not
knowing gender does not
hurt POS.
�
Centurion
customers popping up.
Personal
word of warning, the data
quality will be always be
worse than you expect, you
can
count on
this. Everybody says that
other people have dirty data
(like everyone thinks they
will
win
the lottery and other people
will have an accident), but my d
ata is clean. I don't
believe you;
your
data is always dirty. You
need to allocate time and
resources to facilitate the data
cleanup. In
the
next series of lectures, we
will talk about a methodology using
TQM techniques and apply
to
DWH
data quality. There is a
whole methodology on how to deliver
data quality in a
data
warehouse
environment. This is just a
warning, data quality is
always worse than you think
it is.
You have
used data for transaction
processing; it does not mean
it is good for decision suppo
rt.
Everybody
always underestimate how
dirty their data is. It is
not a few hundred rows of
dirty
data.
Data is always dirtier than
you think. I have not seen a single
business environment that
has
data
that is as clean as it should
be. Especially those things
required for decision making.
Most
people
concentrate on data quality on
numbers, making sure the
amounts are right, make
sure the
accounts
are right those kinds of
things because you need
those to print statements to do
business.
But
for decision making I need
different things. I need to
know the gender of the
customer to
understand my
market place. I don't need
to know the gender of the
customer to process a
transaction. So
basically nobody cares about it,
and they put any garbage
they want in there
and
that
becomes a problem later on. Absolutely do not
assume the data is clean,
assume the opposite,
assume
the data is dirty and help
prove it otherwise.
ETL
vs. ELT
There are
two fundamental approaches to data
acquisition:
ETL:
Extract, Transform, Load in
which data transformation takes
place on a separate
transformation
server.
ELT:
Extract, Load, Transform in which
data transformation takes place on
the data warehouse
server.
Combination of
both is also possible
You
want to have a data flow
driven architecture that you
understand these points i.e.
what data is
required
and how does it flow in
the system driven by the
meta data. Once we have
those data
flows
then we can parallelize. You
leverage pre -packaged tool
for the transformation ste
ps
whenever
possible. But then again
have to look at the
practical realities of the market
place.
That's
why I say whenever possible.
Whenever possible partially means
whenever economically
feasible.
135
In the
architecture, ETL presents
itself very suitable for
data parallelism. Because I have got
tons
of data
and I want to apply operations
consistently across all of
that data. So data parallelism
is
almost
always used and you may
use pipeline parallelism assuming I do
not need too many
sources so on.
The difficulty of doing this
parallelization by hand is very
high. Because if you
want to
write a parallel program say a
parallel C program, like parallel
pro or something like
that,
it is very
difficult. Again it is not just
writing a parallel program, but you a lso
need to make sure it
works
with check-points restarts
and/or error conditions and
all those things. I suspect
that in your
environment, but
this is true for NADRA and
PTML, that use the
database to do the
parallelization.
So a different kind of approach, what if
you are not willing to buy a tool
that costs
US$
200,000?
This is a
different kind of approach
called ELT which is Extract
Load Transform. We extract,
we
load into
the database and then we
transform in the parallel database.
Then we get all
the
parallelism for
free, because you already have a parallel
database. You don't have to buy
a
separate
tool in order to get the
parallelization.
136
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orr’s Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling