 |
Need of Data Warehousing |
| Why a DWH, Warehousing >> |

Lecture
Handout
Data
Warehousing
Lecture
No. 01
Why
Data Warehousing?
�
The
world is changing (actually changed),
either change or be left
behind.
�
Missing the
opportunities or going in the
wrong direction has prevented us
from
growing.
�
What is
the right direction?
�
Harnessing
the data, in a knowledge driven
economy.
The
world economy has moved
form the industrial age into
information driven knowledge
economy.
The information age is
characterized by the computer
technology, modern
communication
technology and Internet technology;
all are popular in the
world today.
Governments around
the globe have realized potential of
information, as a "multi-factor" in
the
development of
their economy, which not
only creates wealth for the
society, but also affects
the
future of
the country. Thus, many
countries in the world have
placed the modern
information
technology
into their strategic plans.
They regard it as the most
important strategic resource
for
the development
their society, and are
trying their best to reach
and occupy the peak of
the
modern
information driven knowledge
economy.
What is
the right direction?
Ever
since the IT revolution that
happened more than a decade
ago every government has
been
trying
and tried to increase our
software exports. But have
persistently failed to get
the desired
results. I
happened to meet a gentleman
who got venture capital of
several million US dollars
and
I asked
him why our software export
has not gone up? His
answer was simple, "we
have been
investing in
outgoing or outdated tools and
technologies". We have also
been just following
India,
without thinking for a
moment, what India is today,
started maybe a decade ago.
So my
next
question was "what should we
be doing today?" His answer
was "we have captured
and
stored
data for a long time,
now it is time to explore and make
use of that data". There is
a saying
that "a
fool and his money
are soon parted", since that
gentleman was rich and is
still rich, hence
he does
qualify to be a wise man,
and his words of wisdom to be paid attention
to.
The
Need for a Data
Warehouse
"Drowning in
data and starving for
information"
"Knowledge is
power, Intelligence is absolute
power!"
1
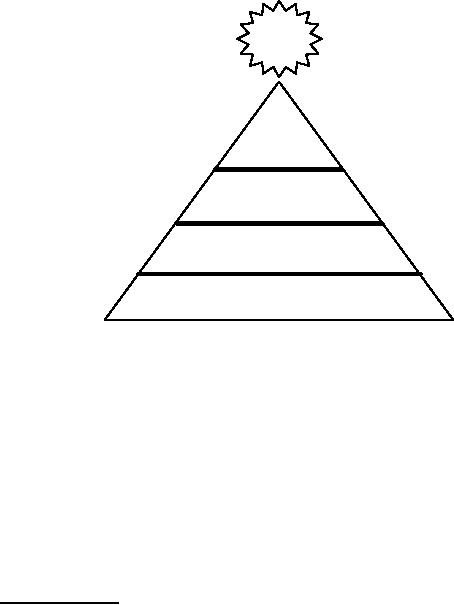
$
POWER
Intelligence
Knowledge
Information
Data
Figure-1.1:
Relationship between Data,
Information, Knowledge &
Intelligence
Data is defined
as numerical or other facts
represented or recorded in a form
suitable for
processing by
computers. Data is often the
record or result of a transaction or an operation
that
involves
modification of the contents of a
database or insertion of rows in tables.
Information in
its
simplest form is processed
data that is meaningful. By processing,
summarizing or analyzing
data,
organizations create information.
For example the current
balance, items sold, money
made
etc.
This information should be
designed to increase the knowledge of
the individual, therefore,
ultimately being
tailored to the needs of the
recipient. Information is processed
data so that it
becomes useful
and provides answers to questions
such as "who", "what", "where",
and "when".
Knowledge, on
the other hand is an application of
information and data, and
gives an insight by
answering the
"how" questions. Knowledge is also
the understanding gained through
experience
or study.
Intelligence is appreciation of "why",
and finally wisdom (not
shown in the figure
-1.1)
is the
application of intelligence and experience
toward the attainment of
common goals, and
wise
people are powerful.
Remember knowledge is power.
Historical
Overview
It is
interesting to note that DSS
(Decision Support System) processing as
we know it today has
reached
this point after a long
and complex evolution, and
yet it continues to evolve.
The origin
of DSS
goes back to the very early
days of computers.
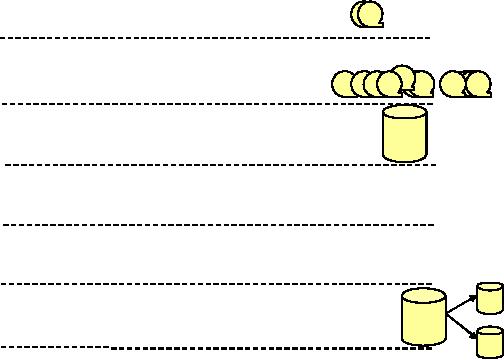
Figure -1.2
shows the historical overview or
the evolution of data
processing from the early
1960s
upto 1980s. In
the early 1960s, the world
of computation consisted of exclusive
applications that
were executed on
master files. The applications featured
reports and programs, using
languages
like
COBOL and punched cards
i.e. the COBOLian era.
The master files were stored
on magnetic
tapes,
which were good for storing a large
volume of data cheaply, but
had the drawback of
needing to be
accessed sequentially, and being
very unreliable (ask your
system administrator
even
today about tape backup
reliability). Experience showed
that for a single pass of a
magnetic
2
tape
that scanned 100% of the
records, only 5% of the
records, sometimes even less were
actually
required. In addition,
reading an entire tape could take anywhere
from 20-30 minutes,
depending
on the
data and the processing
required.
1960
Master Files
& Reports
1965
Lots of
Master files!
1970
Direct
Access Memory &
DBMS
�
1975
Online high
performance transaction
processing
:
1980
PCs and
4GL Technology
(MIS/DSS)
1985
Extract
programs, extract
processing
1990
"
The legacy
system's web
Figure-1.2:
Historical Overview of use of Computers
for Data
Processing
Around
the mid-1960s, the growth of
master files and magnetic
tapes exploded. Soon master
files
were used at
every computer installation.
This growth in usage of
master files, resulted in
huge
amounts of
redundant data. The
spreading of master files
and massive redundancy of
data
presented
some very serious problems,
such as:
�
Data
coherency i.e. the need to
synchronize data upon
update.
�
Program
maintenance complexity.
�
Program
development complexity.
�
Requirement of additional
hardware to support many
tapes.
In a nut -shell,
the inherent problems of
master files because of the
limitations of the medium
used
started to become a bottleneck. If we
had continued to use only
the magnetic tapes, we
may
not
have had an Information
revolution! Consequently, there
would have never been large,
fast
MIS
(Management Information Systems)
systems, ATM systems,
Airline Flight
reservation
systems,
maybe not even Internet as we know
it. As one of my teachers
very rightly said,
"every
problem is an
opportunity" therefore, the ability to
store and manage data on
diverse media (other
3
than
magnetic tapes) opened up
the way for a very
different and more powerful
type of
processing
i.e. bringing the IT and
the business user together
as never before.
The advent of
DASD
By 1970s, a new
technology for the storage
and access of data had
had been introduced.
The
1970s
saw the advent of disk
storage, or DASD (Direct
Access Storage Device). Disk
storage
was
fundamentally different from magnetic
tape storage in the sense
that data could be
accessed
directly on
DASD i.e. non-sequentially.
There was no need to go all
the way through records
1,
2, 3, . . . k so as to
reach the record k + 1. Once
the address of record k + 1 was
known, it was a
simple
matter to go to record k + 1 directly. Furthermore,
the time required to go to record k +
1
was
significantly less than the
time required to scan a magnetic
tape. Actually it took
milliseconds to
locate a record on a DASD
i.e. orders of magnitude
better performance than
the
magnetic
tape.
With
DASD came a new type of
system software known as a DBMS (Data
Base Management
System).
The purpose of the DBMS
was to facilitate the programmer to
store and access data
on
DASD. In
addition, the DBMS took care of
such tasks as storing data on
DASD, indexing data,
accessing it
etc. With the winning
combination of DASD and DBMS
came a technological
solution to the
problems of magnetic tape
based master files. When we
look back at the mess
that
was
created by master files and
the mountains of redundant
data aggregated on them, it is
no
wonder
that database is defined as a single
source of data for all
processing and a prelude to a
data
warehouse i.e. "a single
source of truth".
PC &
4GL
By the
1980s, more and new
hardware/software, such as PCs and 4GLs
(4th Generation
Languages)
began to come out. The
end user began to take up
roles previously unimagined
i.e.
directly
controlling data and
systems, outside the domain of
the classical data center.
With PCs
and
4GL technology the notion
dawned that more could be done with
data than just
servicing
high-performance
online transaction processing
i.e. MIS (Management
Information Systems)
could be developed to
run individual database
applications for managerial
decis ion making
i.e.
forefathers of today's
DSS. Previously, data and IT
were used exclusively to direct
detailed
operational
decisions. The combination of PC and
4GL introduced the notion of a
new paradigm
i.e. a single
database that could serve both
operational high performance transaction
processing
and
(limited) DSS, analytical
processing, all at the same
time.
The
extract program
Shortly after
the advent of massive online
high-performance transactions, an innocent
looking
program called
"extract" processing, began to show
up.
The
extract program was the
simplest of all programs of
its time. It scanned a file
or database,
used
some criteria for selection,
and, upon finding qualified
data, transported the data
into
another
file or database. Soon the
extract program became very attractive,
and flooded the
information
processing environment.
The
spider web
Figure 1.2
shows that a "spider web" of
extract processing programs
began to form. First,
there
were
extracts. Then there were
extracts of extracts, then
extracts of extracts of extracts,
and it
went on. It
was common for large
companies to be doing tens of
thousands of extracts per
day.
This
pattern of extract processing
across the organization soon
became a routine activity, and
even a
name was coined for
it. Extract processing gone
out of control produced what was
called
4
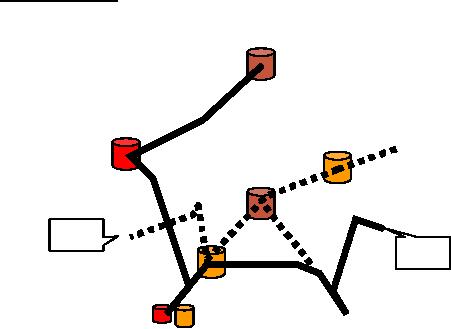
the
"naturally evolving architecture".
Such architectures occurred when an
organization had a
relaxed
approach to handling the whole
process of hardware and software
architecture. The
larger
and more
mature the organization; the
worse was the problems of
the naturally evolving
architecture.
Taken jointly,
the extract programs or naturally
evolving systems formed a
spider web, also
called "legacy
systems" architecture.
Crisis of
Credi bility
What is the financial health of my
company?
"
?
--
:�
4
�
+10%
-10%
:
4
Figure-1.3:
Crisis of Credibility: Who is
right?
Consider
the CEO of an organization who is
interested in the financial
health of his company.
He
asks
the relevant departments to
work on it and present the
results. The organization
is
maintaining
different legacy systems,
employs different extract
programs and uses
different
external
data sources. As a consequence,
Department -A which uses a
different set of data
sources,
external
reports etc. as compared to Department-B
(as shown in Figure -1.3) comes
with a
different
answer (say) sales up by
10%, as compared to the
Department -B i.e. sales
down by 10%.
Because
Department-B used another
set of operational systems, data
bases and external
data
sources.
When CEO receives the two
reports, he does not know
what to do. CEO is faced with
the
option of making
decisions based on politics and
personalities i.e. very subjective
and non -
scientific. This
is a typical example of the crisis in
credibility in the naturally
evolving
archit
ecture. The question is
which group is right? Going with
either of the findings could
spell
disaster, if
the finding turns about to
be incorrect. Hence the second important
question, result of
which
group is credible? This is very hard to
judge, since neit her had malicious
intensions but
both got a
different view of the
business using different
sources.
5
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orr’s Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling