 |

CS201
Introduction to Programming
Lecture
Handout
Introduction
to Programming
Lecture
No. 19
Reading
Material
Deitel
& Deitel - C++ How to
Program
Chapter
6
Summary
·
Sequential
Access Files (Continued)
·
Last
Lecture Reviewed
·
Random
Access Files
- Position in a
File
- Setting the
Position
- Example of
seekg() and tellg()
Functions
- Example of
Data Insertion in the Middle
of a File
- Efficient
Way of Reading and Writing
Files
- Copying a
File in Reverse Order
·
Sample
Program 1
·
Sample
Program 2
·
Exercises
·
Tips
Sequential
Access Files
(Continued)
In the
last lecture, we discussed
little bit about Sequential
Access Files under
the
topic of File Handling.
Sequential Access Files are
simple character
files.
What
does the concept of
sequential access mean?
While working with
the
sequential
access files, we write in a
sequence, not in a random
manner. A
similar
method is adopted while
reading such a file.
In
today's lecture, we will
discuss both the topics of
File Handling and
Random
Access
Files.
Page
221

CS201
Introduction to Programming
Before going
ahead, it is better to recap of
File Handling discussed in
the
previous
lecture. Let's refresh the
functions or properties of File streams
in our
minds.
Last
Lecture Reviewed
It is so far
clear to all of us that we
use open
() function
to open files.
Similarly,
to close
a file close
() function
is used. open
() has
some parameters in
its
parenthesis
as open
(filename, mode) but
close
() brackets
remain empty as it
does
not have any
parameter.
A file
can be opened for reading by
using the open
() function.
It can also be
opened
for writing with the
help of the same open
() function
. But different
argument
value will be needed for
this purpose. If we are
opening for reading
with
ifstream
(Input
File Stream), a simple
provision of the filename
is
sufficient
enough, as the default mode is
for reading or input. We can
also
provide an
additional argument like open
("filename", ios::in). But
this is not
mandatory
due to the default behavior of
ifstream.
However,
for ofstream
(Output
File Stream), we have
several alternatives. If
we open a
file for writing, there is
default mode available to destroy
(delete) the
previous
contents of the file,
therefore, we have to be careful here. On
the other
hand, if
we don't want to destroy the
contents, we can open the
file in append
mode
(ios::app). ios:trunc
value
causes the contents of the
preexisting file by
the
same name to be destroyed
and the file is truncated to
0 length.
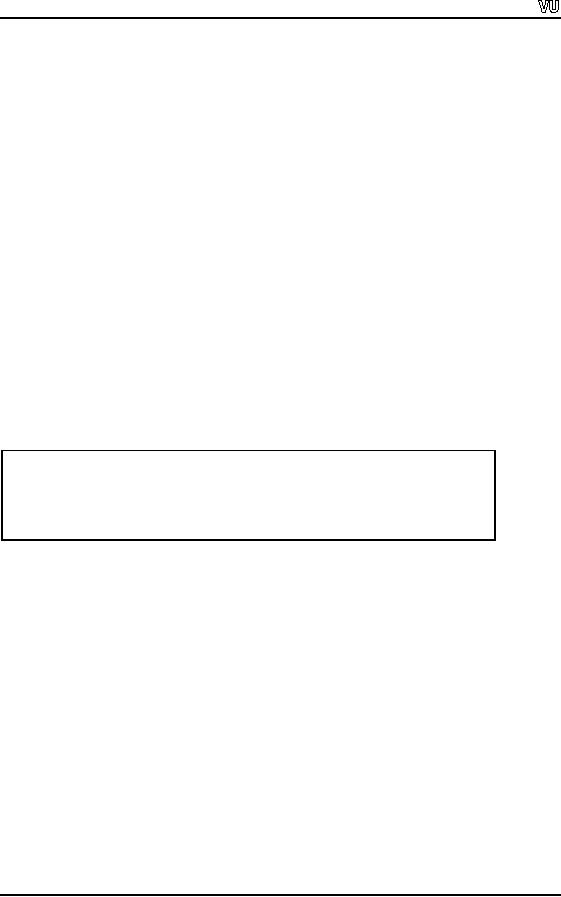
/*
Following program writes an
integer, a floating-point value,
and
a
character to a file called `test'
*/
#include
<iostream.h>
#include
<fstream.h>
main(void)
{
ofstream
out("test"); //Open in default output
mode
if ( !out
)
{
cout
<< "Cannot open file";
return
1;
}
out
<< 100 << " " << 123.12 <<
"a";
out.close();
Page
222

CS201
Introduction to Programming
return
0;
}
If you
want to open a file for
writing at random positions forward
and
backward,
the qualifier used is ios:ate. In this
case, the file is at first
opened
and
positioned at the end. After
that, anything written to the
file is appended at
the
end. We will discuss how to
move forward or backward for
writing in the
file
later in this
lecture.
/*
Following program reads an
integer, a float and a
character from
the
file created by the
preceding program. */
#include
<iostream.h>
#include
<fstream.h>
main(void)
{
char
ch;
int
i;
float
f;
ifstream
in("test"); //Open in default output
mode
if(
!in )
{
cout
<< "Cannot open file";
return
1;
}
in >>
i;
in >>
f;
/* Note
that white spaces are
being ignored, you can
turn
this
off using unsetf(ios::skipws) */
in >>
ch;
cout
<< i << " " << f << " " << ch
;
in.close();
return
0;
}
Besides
open()
and
close
() functions, we
have also discussed how to
read and
write
files. One way was character
by character. This means if we
read (get)
from a
file; one character is read
at a time. Similarly, if we write (put),
one
Page
223

CS201
Introduction to Programming
character
is written to the file.
Character can be interpreted as a byte
here. On
the
other hand, the behavior of
stream extraction operator (>>) and
stream
insertion
operator (<<) is also
valid as we just saw in the
simple programs
above. We
will discuss this a little
more with few new properties
in this lecture.
/* Code
snippet to copy the file
`thisFile' to the file
`thatFile' */
ifstream
fromFile("thisFile");
if
(!fromFile)
{
cout
<< "unable to open 'thisFile' for
input";
}
ofstream
toFile ("thatFile");
if (
!toFile )
{
cout
<< "unable to open 'thatFile' for
output";
}
char c
;
while
(toFile &&
fromFile.get(c))
{
toFile.put(c);
}
This
code:
- Creates an
ifstream
object called
fromFile with a default mode of
ios::in
and
connects it to thisFile. It
opens thisFile.
- Checks the
error state of the new
ifstream
object
and, if it is in a failed
state,
displays
the error message on the
screen.
- Creates an
ofstream
object called
toFile with a default mode of
ios::out
and
connects
it to thatFile.
- Checks the
error state of toFile as
above.
- Creates a
char variable to hold the
data while it is
passed.
- Copies the
contents of fromFile to toFile
one character at a
time.
It is, of
course, undesirable to copy a file
this way, one character at a
time.
This
code is provided just as an example of
using fstreams.
We have
also discussed a function getline
(),
used to read (get) one
line at a
time.
You have to provide how many
characters to read and what
is the
delimiter.
Because this function treats
the lines as character strings. If
you use it
to read
10 characters, it will read 9
characters from the line
and add null
character
(`\0') at the end
itself.
Page
224

CS201
Introduction to Programming
You
are required to experiment with
these functions in order to
understand
them
completely.
Page
225
CS201
Introduction to Programming
Random
Access Files
Now we
will discuss how to access
files randomly, forward and
backward.
Before
moving forward or backward within a
file, one important factor is
the
current
position inside the file.
Therefore, we must understand that
there is a
concept
of file position (or position inside a
file) i.e. a pointer into the
file.
While
reading from and writing
into a file, we should be
very clear from where
(which
location inside the file)
our process of reading or
writing will start.
To
determine
this file pointer position inside a
file, we have two functions
tellg()
and
tellp().
Position in a
File
Let's
say we have opened a file
stream myfile
for
reading (getting),
myfile.tellg
() gives us
the current get position of
the file pointer. It returns
a
whole
number of type long, which
is the position of the next
character to be
read
from that file. Similarly,
tellp
() function
is used to determine the
next
position
to write a character while
writing into a file. It also
returns a long
number.
For
example, given an fstream
object
aFile:
Streampos
original = aFile.tellp(); //save
current position
aFile.seekp(0,
ios::end);
//reposition to
end of file
aFile <<
x;
//write a
value to file
aFile.seekp(original);
//return to
original position
So tellg
() and
tellp
() are
the two very useful functions
while reading from or
writing
into the files at some
certain positions.
Setting
the Position
The
next thing to learn is how
can we position into a file
or in other words how
can we
move forward and backward
within a file. Suppose we
want to open a
file
and start reading from
100th character. For this, we
use seekg
() and
seekp
()
functions. Here
seekg
() takes us
to a certain position to start
reading from
while
seekp
() leads to
a position to write into.
These functions seekg
() and
seekp
() requires
an argument of type long
to
let them how many bytes to
move
forward
or backward. Whether we want to move
from the beginning of a
file,
current
position or the end of the
file, this move forward or
backward
operation,
is always relative to some position..
From the end of the
file, we can
only move
in the backward direction. By using
positive value, we tell
these
functions to
move in the forward
direction .Likewise, we intend to move in
the
backward
direction by providing a negative
number.
Page
226

CS201
Introduction to Programming
By
writing:
aFile.
seekg (10L, ios::beg)
We are
asking to move 10 bytes
forward from the begining of
the file.
Similarly,
by writing:
aFile.
seekg (20L, ios::cur)
We are
moving 20 bytes in the
forward direction starting from
the current
position.
Remember, the current
position can be obtained
using the tellg
()
function.
By
writing:
aFile.
seekg (-10L, ios:cur)
The
file pointer will move 10
bytes in the backward direction
from the current
position.
With seekg
(-100L, ios::end), we are
moving in the backward
direction
by 100 bytes starting from
the end of the file. We
can only move in
the
forward direction from the
beginning of the file and backward
from the end
of the
file.
You
are required to write a program to
read from a file, try to
move the file
pointer
beyond the end of file
and before the beginning of
the file and
observe
the
behavior to understand it
properly.
seekg()
and tellg() Functions
One of
the useful things we can do
by employing these functions is to
determine
the
length of the file. Think
about it, how can we do
it.
In the
previous lectures, we have discussed
strlen
() function
that gives the
number of
characters inside a string. This function
can also be used to
determine
the length of the string placed inside an
array. That will give us
the
number of
characters inside the string instead of
the array length. As
you
already
know that the length of the
array can be longer than the
length of the
string inside
it. For example, if we declare an
array of 100 characters but
store
"Welcome
to VU" string in it, the length of the
string is definitely smaller than
the
actual size of the array and
some of the space of the
array is unused.
Similarly
in case of files, the space
occupied by a file (file size)
can be more
than
the actual data length of
the file itself.
Why
the size of the file can be
greater than the actual
data contained in
that
file?
The answer is little bit
off the topic yet it will be
good to discuss.
As you
know, the disks are electromagnetic
devices. They are very slow
as
compared
to the controlling electronic devices
like Processors and
RAM
(Random
Access Memory). If we want to
perform read or write
operations to
the
disk in character by character fashion,
it will be very wasteful of
computer
time.
Take another example. Suppose
,we want to write a file,
say 53 bytes long
to the
disk . After writing it,
the next file will
start from 54th byte on the
disk.
Page
227

CS201
Introduction to Programming
Obviously,
this is very wasteful
operation of computer time. Moreover, it
is
also
very complex in terms of handling
file storage on the
disk.
To
overcome this problem, disks are
divided into logical blocks
(chunks or
clusters)
and size of one block is the
minimum size to read and
write to the
disk.
While saving a file of 53
bytes, we can't allocate
exactly 53 bytes but
have to
utilize at least one block
of disk space. The remaining
space of the
block
except first 53 bytes, goes
waste. Therefore, normally
the size of the file
(which is
in blocks) is greater than the
actual data length of the
file. When this
file
will be read from the
disk, the whole chunk
(block) is read instead of
the
actual
data length.
By using
seekg
() function,
we can know the actual
data length of the file.
For
that
purpose, we will open the
file and go to the end of
the file by asking
the
seekg
() function
to move 0 bytes from the
end of the file as:
seekg
(0,
ios::end).
Afterwards, (as we are on
end of file position), we
will call tellg
() to
give
the current position in long
number.
This number is the actual
data bytes
inside
the file. We used seekg
() and
tellg
() functions
combination to
determine
the actual data length of a
file.
/* This
is a sample program to determine the
length of a file. The
program
accepts
the name of the file as a
command-line argument. */
#include
<fstream.h>
#include
<stdlib.h>
ifstream
inFile;
ofstream
outFile;
main(int
argc, char **argv)
{
inFile.open(argv[1]);
if(!inFile)
{
cout
<< "Error opening file in
input mode"<< endl;
}
/* Determine
file length opening it for
input */
inFile.seekg(0,
ios::end);
//Go to
the end of the
file
long
inSize = inFile.tellg();
//Get the
file pointer position
cout
<< "The length of the file
(inFile) is: " <<
inSize;
inFile.close();
/* Determine
file length opening it for output
*/
Page
228

CS201
Introduction to Programming
outFile.open(argv[1],
ios::app);
if(!outFile)
{
cout
<< "Error opening file in
append mode"<< endl;
}
outFile.seekp(0,
ios::end);
long
outSize = outFile.tellp();
cout
<< "\nThe length of the file
(outFile) is: " << outSize;
outFile.close();
}
Run
this program to see its
output that shows different results
for both input
and
output modes. Discuss it on discussion
board.
Data
Insertion in the Middle of a
File
The
question arises why to talk
about seekg
() and
tellg
() functions
before
proceeding
to our original topic of
random access to files. This
can be well-
understood
from the following example.
Let's suppose, we have
written a file
containing
names, addresses and dates
of birth of all students of
our class.
There is
a record of a student, who is
from Sukkur. After
sometime, we come
to know
that the same student
has moved to Rawalpindi. So we
need to update
his
record. But that record is
lying somewhere in the
middle of the file.
How
can we
update it?
We can
search Sukkur
using
seekg
() and
tellg
() functions.
After finding it,
can we
update the word sukkur
with
the Rawalpindi. No. It
is just due to the
fact that
Rawalpindi
is
longer in length than the
word Sukkur
and
the
subsequent
data of Data of Birth of the
student will be overwritten. So
the
structure
of the file is disturbed and
as a result your data file
will be corrupted.
This is
one of the issues to be
taken care of while writing
in the middle of a
sequential
file.
Let's
think again what is the
actual problem. The file is
lying on the disk. We
started
reading that file and
reached somewhere in the
middle of the file to
replace
data at that position. But
the data we are going to
replace is shorter in
length as
compared to the new one.
Consider how is this on the
disk. We need
some
kind of mechanism to cut the
disk, slide it further to make some
space to
insert
the data into. But this is
not practically
possible.
In the
times of COBOL, the Merge
Method was employed to insert data
into
the
middle of the file. The
logic of Merge method is to copy all
the data into a
new
file starting from beginning of the
file to the location where we
want to
insert
data. So its algorithm
is:
- Opened the
data file and a new
empty file.
- Started
reading the data file
from beginning of it.
Page
229

CS201
Introduction to Programming
Kept on
copying the read data
into the new file
until the location we want
to
-
insert
data into is reached.
- Inserted
(appended) new data in the
new file.
- Skipped or jumped the
data in the data file
that is to be overwritten or
replaced.
- Copied (appended)
the remaining part of the
file at the end of the
new file
This is
the only way of inserting
the data in the middle of a
sequential file.
After
this process, you may
delete the old file
and rename the new
file with the
same
name as that of the old
file. This was done in the
past . But now
nowadays,
it is used some time when
the size of the data is not
huge. But
obviously,
it is very wasteful as it takes
lot of time and space in
case of large-
sized
data . The file size can be
in hundred of megabytes or even in
gigabytes.
Suppose,
you have to copy the whole
file just to change one
word. This is just a
wasteful
activity. Therefore, we must have
some other mechanism so that
we
can
randomly read and write
data within a file, without
causing any
disturbance
in the
structure of file.
To
achieve this objective, we have to
have random access file
and the structure
of the
file should be such that it
is not disturbed in case of
updations or
insertions
in the middle . The language
C/C++ does not impose any
structure
on the
file. The file can be
English text or a binary
file. Be sure that a
language
has
nothing to do with it. For a
language, a file is nothing but a
stream of bytes.
In our
previously discussed example of students
of a class, it makes lot of
sense
that
each record of the file (a
student record) occupies the
same space. If the
record
size is different, the updations
will have similar problems as
discussed
above. So
what we need do is to make
sure that size of each
student data is
identical
in the file. And the
space we have decided on is
large enough such
that, if
we wrote Sukkur
into
it, the spaces were there at
the end of it. If we
want to
replace Sukkur
with
Ralwalpindi
or
Mirpur
Khas, it can
fit into the
same
allotted space. It means that
the file size remains the
same and no
destruction
takes place,. So the
constant record length is the
key element in
resolving
that issue of insertion in the
middle of the file without
disturbing the
structure
of the file. Normally, we
also keep some key
(it is a database
terminology)
inside these files. The key
is used to locate the
record. Consider
the
example of students again. Suppose we
had written student's name,
say
Jamil
Ahmed, city
and data of birth, what
could we do to locate the student
to
change
the student's information
from Sukkur
to
Rawalpindi. We could
have
written a
loop to read the names
and to compare it with Jamil
Ahmed to
locate
the
particular record of that student to
replace the city to Rawalpindi. But
this
comparison
of names is expensive in terms of
computation. It could be nicer to
store a
serial number with each
record of the students. That
serial number will
be unique
for each student. It can
also be roll number or ID
number of a
student.
So we can say that replace
the city of the student
with id number 43
to
Rawalpindi. So in
this case, we will also be
doing comparison based on the
basis of
ID numbers of student. Here we have
made a comparison again. But
is
a
number-related comparison, not a string
comparison. It will be even
easier if
Page
230

CS201
Introduction to Programming
the
file is sorted on the basis
of student id numbers which
have no gaps. If the
data is
of 50 students, the first
student's id number is 1 and
last one is 50.
Let's
take this example little further.
Suppose the record of one
student can be
stored in
100 bytes. The student id
field that is also contained
within these 100
bytes is
there in the file to
uniquely identify each
student's record.
If we
want to read the 23rd student's record (with id
23) in the file. One
way is
the
brute force technique discussed earlier
to start a loop from the
beginning of
the
file to the required student
id 23.
We have
added following conditions with
this file.
- Each
student record takes 100
bytes
- The first
ten bytes of a record are
student id number. Student's name
and
City
are 40 characters long respectively
and last 10 bytes are
for Date of
Birth.
- The student
ids are in order (sorted)
and there are no holes in
student ids. If
let's
say there is 50 students
data then the file
will start with id 1
student's
record
and end with id 50 student's
record.
After
becoming aware of the above-mentioned
conditions, can we find a
quick
way of
finding the 23rd's
student data? The answer is
obviously yes as we
know
that
one student's data is taking
100 bytes then 22 student's
data will be 22 *
100 =
2200 bytes. The data
for 23rd's
student starts from
2201st byte and
goes
to
2300th byte. We will
jump first 2200 bytes of
the file using seekg
() function
and
there will be no wastage of
resources as there are no
loops, no if-else
comparisons.
After being aware of
structure of a student's record, we
can go to
the
desired position and perform
update operation wherever needed. We
can
update
the name of the student,
change the name of the
city and correct the
data
of birth
etc. So seekg
() allows us
to jump to any position in
the file.
seekg()
is
used for input file or
for reading from the
file while seekp()
is
used
for
output during the process of writing to
the file. Remember, a file
opened
with
ifstream
is
used for input and
cannot be used for output.
Similarly, a file
opened in
output mode using ofstream
cannot be
used for input mode.
But a
file
opened with the help of
fstream; can be
used for both purposes i.e.
input
and
output. The qualifier ios::in
|| ios::out is passed
into the open
() function
while
opening the file with
fstream
for
both purposes. Why are we
doing the
OR `||'
operation for opening the
file in both the modes.
You might remember
that
when we do OR operation ( if either of
the expression is true ),
the result
becomes
true. The qualifiers ios::in
|| ios::out are flags
and exist in memory
in
the
form of 0's and 1's.
The input flag ios::in
has
one bit on (as 1) and
output
flag
ios::out
possesses
another bit on. When we
perform OR `||' operation
to
these
two flags, the resultant of
this expression contains the
bits as on (as 1)
from
both of the flags. So this
resultant flag bits depict
that the file will be
used
for
both input and output . We
can use this technique of
ORing for other
qualifiers
as well. Remember that it is
not a case of AND. Although,
we want
input
and output , yet we have to do OR
operation ios::in
|| ios::out to
achieve
our
desired behavior.
Page
231

CS201
Introduction to Programming
Lets
see how can these
tricks work
As
discussed in the example of data
updation within a file, what
can happen if
we know
the exact things and want to
replace a q
character
in a sentence? We
should
think of the logic first as
it has always to be with
logic and analysis
that
what
would be algorithm for a problem.
Lets say we wrote a sentence
This
is
an
apple in a file
and want to change it to This
is a sample. The
length of both
the
sentences is same.
/* This
program firstly writes a string
into a file and then
replaces
its
partially. It demonstrates the
use of seekp(), tellp() and
write()
functions.
*/
#include
<fstream>
int
main ()
{
long
pos;
ofstream
outfile;
outfile.open
("test.txt");
// Open
the file
outfile.write
("This is an apple",16); // Write the
string in the file
pos =
outfile.tellp();
// Get
the File pointer
position
outfile.seekp
(pos-7);
// Move 7
positions backward
outfile.write
(" sam",4);
// Write
4 chars in the current
position
outfile.close();
// Close
the file
return
0;
}
Efficient
Way of Reading and Writing
Files
Let's
consider another example. We know
how to read a file character
by
character,
write into another file or
on the screen. If we want to
write into a file
after
reading another file, there
are already enough tools to
get (read) one
character
from a file and put
(write) into the other
one. We can use
inputFile.getc
() to
get a character and outputFile.putc
() to
write a character
into a
file.
As mentioned earlier,
there is very inefficient
way of doing things . We also
know
that for reading and
writing to disk, processing in
chunks is more
efficient.
Can we handle more data than
a single byte or a single line?
The
answer is
yes. We can use read
() and
write
() functions
for this purpose.
These
functions are binary functions and
provided as a part of the
stream
functions.
The term binary means
that they read and
write in binary mode ,
not
in
characters. We tell a location in
memory to read
() function
to write the read
data
and with the number of
bytes to read or write.
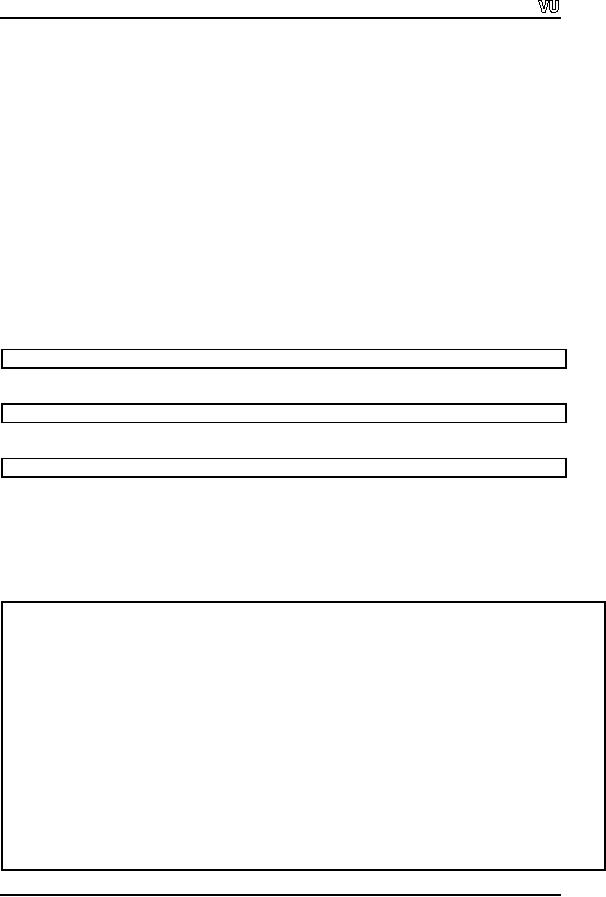
Usually, read(arrayname,
number of
bytes) e.g. read(a,
10).
Page
232
CS201
Introduction to Programming
Now
depending on our computer's memory, we
can have a very large
data in it.
It may be
64K.
You
are required to write two
programs:
One
program will be used to get to
read from a file and
put to write into
the
other
file. Prepare a simple
character file using notepad
or any other editor of
your
choice. Put some data inside
and expand the size of the
data in the file by
using
the copy-paste functions. A program
can also be written to make
this big-
sized
data file. The file size
should be more than 40K preferably.
Read this file
using
getc
() and
write it another file using
putc
().
Try to note down the
time
taken by
the program. Explore the
time
() function
and find out how to
use it in
your
program to note the processing
time.
Write
another program to do the same
operation of copying using
read and
write
functions. How to do it?
First
declare a character
array:
-
char
str[10000];
Call
the read function for
input file.
-
myInputFile.read(str,
10000);
To write
this, use the write function
for output file.
-
myOutputFile.write(str);
Here, a
loop will be used to process
the whole file. We will
see that it is much
faster
due to being capable of
reducing the number of calls to
reading and
writing
functions. Instead of 10000 getc
() calls, we
are making only one
read
()
function
call. The performance is
also made in physical reduced
disk access
(read
and write). Important part
of the program code is given
below:
ifstream
fi;
ofstream
fo;
...
...
fi.open("inFilename",
ios::in); // Open the
input file
fo.open("outFilename",
ios::out); // Open the output
file
fi.seekg(0,ios::end);
// Go the
end of input file
j =
fi.tellg();
// Get
the position
fi.seekg(0,ios::beg);
// Go to
the start of input
file
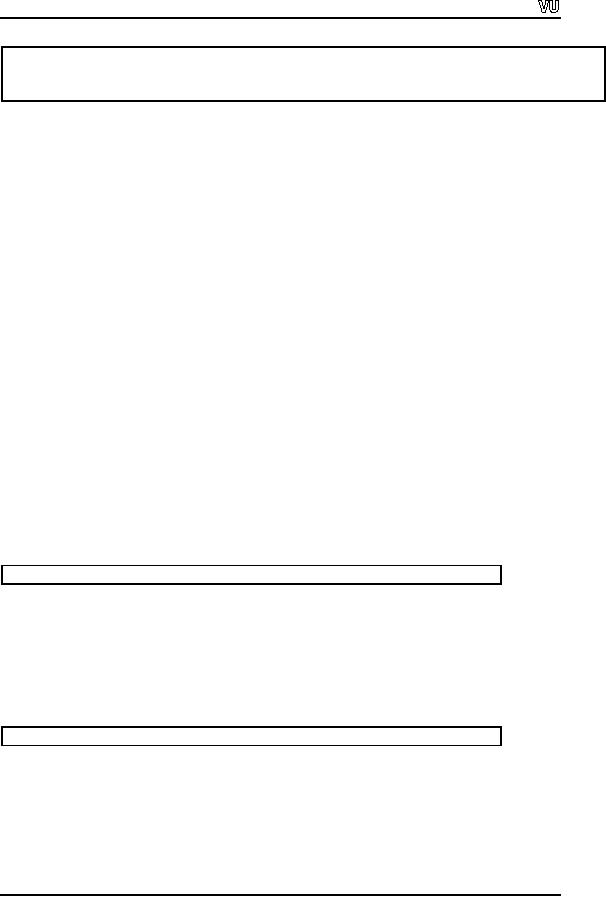
for(i =
0; i < j/10000; i++)
{
fi.read(str,
10000);
// Read
10000 bytes
fo.write(str,
10000);
// Wrote
10000 bytes
}
fi.read(str,
j-(i * 10000));
// Read
the remaining bytes
Page
233
CS201
Introduction to Programming
fo.write(str,
j-(i * 10000));
// Wrote
the remaining bytes
fi.close();
// Close
the input file
fo.close();
// Close
the output file
The
fine points in this exercise
are left open to discover.
Like what happens if
the
file length is 25199 bytes.
Will our above solution
work? Definitely, It
will
work
but you have to figure
out what happened and
why does it work. Has
the
last
read
() function
call read 10000 bytes?
You have to take care of
few things
while
doing file handling of character and
binary files. Remember that
the size
of the
physical file on the disk
may be quite different from
the actual data
length
contained in the
file.
Copying a
File in the Reverse Order
We can
also try copying a file in
reverse. Suppose, we want to
open a text file
and
write it in reverse order in a
new file after reading.
That means the last
byte
of the
input file will be the
first byte of the output file,
second last byte of
the
input
file will be the second byte
of the output file until the
first byte of the
input
file becomes the last
byte of the output file.
How will we do it?
Open
the input file. One of
the ways of reading the
files is to go to its end
and
start
reading in the reverse
direction byte by byte. We have
already discussed ,
how to go
to the end the file
using seekg
(0, ios:end). By now,
you will be
aware
that while reading, the
next byte is read in the
forward direction.
With
the
use of seekg
(0, ios:end), we are
already at end of the file.
Therefore, if
want to
read a byte here it will
not work. To read a byte, we
should position file
pointer
one byte before the byte we
are going to read. So we don't
want to go to
the
end but one byte before it
by using:
aFile.seekg
(-1, ios::end);
We also
know that whenever we read a
byte, the file pointer
automatically
moves
one byte forward so that it is
ready to read the next byte.
But in our case,
after
positioning, the file pointer 1 byte
before the end of file
and reading 1 byte
has
caused the file pointer to
move automatically to the
end of file byte and
there is
no further data of this file to
read. What we need to do now
to read the
next byte
(second last byte of input
file) in reverse order is to
move 2 positions
from
the end of file:
aFile.seekg
(-2, ios::end);
Generically,
this can also be said as
moving two positions back
from the
current
position of the file pointer. It
will be ready to read the
next character.
This is
little bit tricky but
interesting. So the loop to process
the whole file
will
run in
the same fashion that after
initially positioning file pointer at
second last
byte, it
will keep on moving two
positions back to read the
next byte until
beginning of
the input file is reached.
We need to determine the beginning
of
Page
234
CS201
Introduction to Programming
the
file to end the process
properly. You are required to
workout and complete
this
exercise, snippet of the program is
given below:
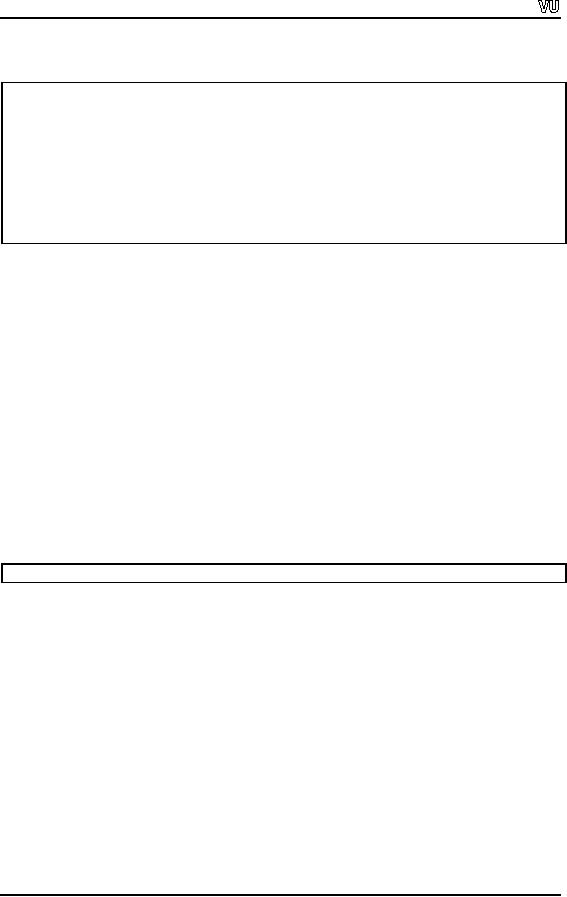
aFile.seekg(-1L,
ios::end);
while(
aFile )
{
cout
<< aFile.tellg() << endl;
aFile.get(c);
aFile.put(c);
aFile.seekg(-2L,ios::cur)
;
}
Remember,
generally, if statement is very expensive
computation-wise. It takes
several
clock cycles. Sequential reading is
fairly fast but a little
bit tedious. To
reach to
100th location, you
have to read in sequence one
by one. But if you
use
seekg
() function
to go to 100th
location, it is
very fast as compared to
the
sequential
reading.
As
discussed, in terms of speed
while doing file handling are
read
() and
write
()
functions.
The thing needed to be taken
care of while using these
functions is
that
you should have enough
space in memory available. We have
discussed
very
simple example of read
() and
write
() functions
earlier . But it is more
complex
as you see in your text
books. Don't get confused,
you remember we
used
array . Array name is a pointer to
the beginning of the array.
Basically, the
read
() requires
the starting address in memory where to
write the read
information
and then it requires the
number of bytes to read. Generally,
we
avoid
using magic numbers in our
program. Let's say we want
to write an int
into a
file, the better way is to
use the sizeof
() function
that can write an
integer
itself without specifying
number of bytes. So our
statement will be
like:
aFile.write
(&i, sizeof (i));
What
benefits one can get
out of this approach?. We
don't need to know
the
internal
representation of a type as same code
will be independent of
any
particular
compiler and portable to
other systems with different
internal
representations.
You are required to write
little programs and play
with this
function
by passing different types of
variables to this function to
see their
sizes.
One can actually know
that how many bytes take
the char type variable,
int type
variable or a double or a float type
variable.
You
are required to write a program to
write integers into a file
using the write
()
function.
Open a file and by running a
loop from 0 to 99, write
integer
counter
into the file. After
writing it, open the
file in notepad. See if you
can
find
integers inside of it. You
will find something totally
different. Try to
figure
out
what has happened. The clue
lies in the fact that this
was a binary write. It
is more
like the internal representation of
the integers not what
you see on the
screen.
You are required to play
with it and experiment it by writing
programs.
Page
235

CS201
Introduction to Programming
It is
mandatory to try out the
above example . Also experiment the
use of read
()
function
to read the above written
file of integers and print
out the integers
on the
screen. Can you see
correct output on the screen? Secondly,
change the
loop
counter to start from 100 to
199, write it using write
() function
and print
it on the
screen after reading it into
an integer variable using read
() function.
Does
that work now? Think
about it and discuss it on
discussion board.
Sample
Program 1
/* This
is a sample program to demonstrate
the use of open(), close(), seekg(),
get() functions and streams. It expects a
file named my-File.txt in
the
current directory
having some data strings inside it.
*/
#include
<fstream.h>
#include
<stdlib.h>
/*
Declare the stream objects
*/
ifstream
inFile;
ofstream
scrn, prnt;
main()
{
char
inChar;
inFile.open("my-File.txt",
ios::in); // Open the file
for input
if(!inFile)
{
cout
<< "Error opening file"<<
endl;
}
scrn.open("CON",
ios::out); // Attach the console
with the output
stream
while(inFile.get(inChar))
// Read
the whole file one
character at a time
{
scrn
<< inChar;
// Insert
read character to the output
stream
}
scrn.close();
// Close
the output stream
inFile.seekg(0l,
ios::beg);
// Go to
the beginning of the
file
prnt.open("LPT1",
ios::out); // Attach the output
stream with the LPT1
port
while(inFile.get(inChar))
// Read the whole file
one character at a
time
{
prnt <<
inChar;
// Insert
read character to the output
stream
}
prnt.close();
// Close
the output stream
inFile.close();
// Close
the input stream
}
Page
236

CS201
Introduction to Programming
Sample
Program 2
/* This
sample code demostrates the
use of fstream and seekg()
function. It will create
a
file
named my-File.txt write
alphabets into it, destroys
the previous contents
*/
#include
<fstream.h>
fstream
rFile;
//
Declare the stream
object
main()
{
char
rChar;
/* Opened
the file in both input
and output modes */
rFile.open("my-File.txt",
ios::in || ios::out);
if(!rFile)
{
cout
<< "error opening file"<<
endl;
}
/* Run
the loop for whole
alphabets */
for (
rChar ='A'; rChar <='Z';
rChar++)
{
rFile
<< rChar;
// Insert
the character in the
file
}
rFile.seekg(8l,
ios::beg); // Seek the beginning
and move 8 bytes
forward
rFile
>>rChar;
// Take
out the character from
the file
cout
<< "the 8th character is " <<
rChar ;
rFile.seekg(-16l,
ios::end); // Seek the end
and move 16 positions
backword
rFile
>>rChar;
// Take
out the character at the
current position
cout
<< "the 16th character from
the end is " << rChar
;
rFile.close();
// Close
the file
}
Exercises
1. Write
a program to concatenate two files.
The filenames are provide as
command-line
arguments. The argument file
on the right (first
argument)
will be
appended to the file on the
left (second
argument).
2. Write
a program to read from a file,
try to move the file pointer
beyond the
end of
file and before the
beginning of the file and
observer the
behavior.
Page
237

CS201
Introduction to Programming
3. Write
a program reverse
to
copy a file into reverse
order. The program
will
accept
the arguments like:
reverse
org-file.txt
rev-file.txt
Use the
algorithm already discussed in
this lecture.
4. Write
a program to write integers
into a file using the
write
() function.
Open a
file and by running a loop
from 0 to 99, write integer
counter into
the
file. After writing it,
open the file in notepad.
See if you can
find
integers
inside it.
Tips
·
Be careful
for file mode before
opening and performing any
operation on a file.
·
The
concept of File Pointer is essential in
order to move to the desired
location in
a
file.
·
tellg(), seekg(), tellp()
and
seekp()
functions
are used for random
movement
(backward
and forward) in a
file.
·
There
are some restrictions (conditions) on a
file to access it randomly.
Like its
structure
and record size should be
fixed.
·
Ability
to move backward and forward at random
positions has given significance
performance
to the applications.
·
Binary
files (binary data) can
not be viewed properly inside a text
editor because
text
editors are character
based.
Page
238
Table of Contents:
- What is programming
- System Software, Application Software, C language
- C language: Variables, Data Types, Arithmetic Operators, Precedence of Operators
- C++: Examples of Expressions, Use of Operators
- Flow Charting, if/else structure, Logical Operators
- Repetition Structure (Loop), Overflow Condition, Infinite Loop, Properties of While loop, Flow Chart
- Do-While Statement, for Statement, Increment/decrement Operators
- Switch Statement, Break Statement, Continue Statement, Rules for structured Programming/Flow Charting
- Functions in C: Structure of a Function, Declaration and Definition of a Function
- Header Files, Scope of Identifiers, Functions, Call by Value, Call by Reference
- Arrays: Initialization of Arrays, Copying Arrays, Linear Search
- Character Arrays: Arrays Comparisonm, Sorting Arrays Searching arrays, Functions arrays, Multidimensional Arrays
- Array Manipulation, Real World Problem and Design Recipe
- Pointers: Declaration of Pointers, Bubble Sort Example, Pointers and Call By Reference
- Introduction, Relationship between Pointers and Arrays, Pointer Expressions and Arithmetic, Pointers Comparison, Pointer, String and Arrays
- Multi-dimensional Arrays, Pointers to Pointers, Command-line Arguments
- String Handling, String Manipulation Functions, Character Handling Functions, String Conversion Functions
- Files: Text File Handling, Output File Handling
- Sequential Access Files, Random Access Files, Setting the Position in a File, seekg() and tellg() Functions
- Structures, Declaration of a Structure, Initializing Structures, Functions and structures, Arrays of structures, sizeof operator
- Bit Manipulation Operators, AND Operator, OR Operator, Exclusive OR Operator, NOT Operator Bit Flags Masking Unsigned Integers
- Bitwise Manipulation and Assignment Operator, Programming Constructs
- Pre-processor, include directive, define directive, Other Preprocessor Directives, Macros
- Dynamic Memory Allocation, calloc, malloc, realloc Function, Dangling Pointers
- History of C/C++, Structured Programming, Default Function Arguments
- Classes and Objects, Structure of a class, Constructor
- Classes And Objects, Types of Constructors, Utility Functions, Destructors
- Memory Allocation in C++, Operator and Classes, Structures, Function in C++,
- Declaration of Friend Functions, Friend Classes
- Difference Between References and Pointers, Dangling References
- Operator Overloading, Non-member Operator Functions
- Overloading Minus Operator, Operators with Date Class, Unary Operators
- Assignment Operator, Self Assignmentm, Pointer, Conversions
- Dynamic Arrays of Objects, Overloading new and delete Operators
- Source and Destination of streams, Formatted Input and Output, Buffered Input/Output
- Stream Manipulations, Manipulators, Non Parameterized Manipulators, Formatting Manipulation
- Overloading Insertion and Extraction Operators
- User Defined Manipulator, Static keyword, Static Objects
- Pointers, References, Call by Value, Call by Reference, Dynamic Memory Allocation
- Advantages of Objects as Class Members, Structures as Class Members
- Overloading Template Functions, Template Functions and Objects
- Class Templates and Nontype Parameters, Templates and Static Members
- Matrices, Design Recipe, Problem Analysis, Design Issues and Class Interface
- Matrix Constructor, Matrix Class, Utility Functions of Matrix, Input, Transpose Function
- Operator Functions: Assignment, Addition, Plus-equal, Overloaded Plus, Minus, Multiplication, Insertion and Extraction