 |

Human
Computer Interaction
(CS408)
VU
Lecture
43
Lecture
43. Information
Retrieval
Learning
Goals
As the
aim of this lecture is to
introduce you the study of
Human Computer
Interaction,
so that after studying this
you will be able to:
� Discuss
how to communicate
� Learn
how to retrieve the
information
Audible
feedback
43.1
In
data-entry environments, clerks
sit for hours in front of
computer screens
entering
data.
These users may well he
examining source documents and
typing by touch
instead
of looking at the screen. If a
clerk enters something
erroneous, he needs to be
informed
of it via both auditory and
visual feedback. The clerk
can then use his
sense
of
hearing to monitor the
success of his inputs while
he keeps his eyes on
the
document.
The
kind of auditory feedback we're
proposing is not
the
same as the beep
that
accompanies
an error message box. In
fact, it isn't beep at all.
The auditory indicator
we
propose as
feedback for a problem is silence.
The
problem with much current
audible
feedback
is the still-prevalent idea
that, rather than positive
audible feedback,
negative
feedback
is desirable.
NEGATIVE AUDIBLE
FEEDBACK: ANNOUNCING USER FAILURE
People
frequently counter the idea
of audible feedback with arguments
that users don't
like
it. Users are offended by
the sounds that computers
make, and they don't like
to
have
their computer beeping at them.
This is likely true based on
how computer
sounds
are widely used today --
people have been conditioned by
these unfortunate
facts:
� Computers
have always accompanied error
messages with alarming
noises.
� Computer
noises have always been
loud, monotonous and
unpleasant.
Emitting
noise when something bad happens is
called negative audible feedback.
On
most
systems, error message boxes
are normally accompanied by loud,
shrill, tinny
"beeps,"
and audible feedback has thus
become strongly associated
them. That beep is a
public
announcement of the user's failure. It
explains to all within
earshot that you have
done something
execrably stupid. It is such a
hateful idiom that most
software
developers
now have an unquestioned
belief that audible feedback
is bad and should
never
again be considered as a part of
interface design. Nothing could be
further from
the
truth. It is the negative
aspect of the feedback that
presents problems, not the
audible
aspect.
Negative
audible feedback has several things
working against it. Because
the negative
feedback
is issued at a time when a
problem is discovered, it naturally takes
on the
characteristics of an
alarm. Alarms are designed to be
purposefully loud, discordant,
and
415

Human
Computer Interaction
(CS408)
VU
disturbing.
They are supposed to wake
sound sleepers from their
slumbers when their
house is
on fire and their lives are
at stake. They are like
insurance because we all
hope
that
they will never be heard. Unfortunately,
users are constantly doing
things that
programs
can't handle, so these actions
have become part of the nor
mal course of
interaction.
Alarms have no place in this
normal relationship, the same
way wt don't
expect
our car alarms to go off
whenever we accidentally change
lanes without using
our
turn
indicators. Perhaps the most
damning aspect of negative audible
feedback is the
implication
that success must be greeted
with silence. Humans like to
know when they are
doing
well. They need
to
know when they are doing
poorly, but that doesn't
mean that they
like to
hear about it. Negative feedback
systems are simply appreciated
less than positive
feedback
systems.
Given
the choice of no noise
versus noise for negative
feedback, people will choose
the former.
Given
the choice of no noise
versus unpleasant noises for
positive feedback,
people
will
choose based on their
personal situation and
taste. Given the choice of
no noise
versus
soft and pleasant noises for
positive feedback, however, people will
choose the
feedback.
We have never given our
users a chance by putting
high-quality, positive audible
feedback
in our programs, so it's no wonder that people
associate sound with bad
interfaces.
POSITIVE AUDIBLE
FEEDBACK
Almost
every object and system
outside the world of
software offers sound to
indicate
success
rather than failure. When we
close the door, we know
that it is latched when we
hear
the
click, but silence tells us
that it is not yet secure. When we
converse with someone and
they
say,
"Yes" or "Uh-huh," we know
that they have, at least
minimally, registered what
was said.
When they
are silent, however, we have
reason to believe that something is
amiss. When we
turn
the key in the ignition
and get silence, we know
we've got a problem. When we flip
the
switch on
the copier and it stays
coldly silent instead of humming, we know
that we've got
trouble. Even
most equipment that we consider
silent makes some noise:
Turning on the
stovetop
returns a hiss of gas and a
gratifying "whoomp" as the
pilot ignites the
burner.
Electric
ranges are inherently less
friendly and harder to use
because they lack that sound
--
they
require indicator lights to tell us of
their status.
When
success with our tools
yields a sound, it is called positive audible
feedback. Our
software
tools are mostly silent; all we
hear is the quiet click of
the keyboard. Hey!
That's
positive audible
feedback. Every time you
press a key, you hear a
faint but positive sound.
Keyboard
manufacturers could make perfectly silent
keyboards, but they don't
because we
depend on
audible feedback to tell us how we
are doing. The feedback doesn't
have to be
sophisticated
-- those clicks don't tell
us much -- but they must be
consistent. If we ever
detect
silence, we know that we have failed to
press the key. The true
value of positive
audible
feedback is that its absence
is an extremely effective problem
indicator.
The
effectiveness of positive audible feedback
originates in human sensitivity. Nobody
likes to
be told
that they have failed. Error
message boxes are negative
feedback, telling the user
that
he has
done something wrong.
Silence can ensure that
the user knows this
without
actually
being told of the failure.
It is remarkably effective, because the
software doesn't
have to
insult the user to
accomplish its ends.
Our
software should give us
constant, small, audible
cues just like our keyboards.
Our
programs
would be much friendlier and
easier to use if they issued
barely audible but
easily
identifiable
sounds when user actions are
correct. The program could issue an
upbeat tone
416

Human
Computer Interaction
(CS408)
VU
every
time the user enters valid
input to a field. If the
program doesn't understand
the
input, it
would remain silent and
the user would be immediately informed of
the problem
and be
able to correct his input
without embarrassment or ego-bruising.
Whenever the
user
starts to drag an icon, the
computer could issue a low-volume
sound reminiscent of
sliding
as the object is dragged.
When it is dragged over
pliant areas, an
additional
percussive
tap could indicate this
collision. When the user
finally releases the
mouse
button,
he is rewarded with a soft, cheerful
"plonk" from the speakers
for a success or with
silence
if the drop was not meaningful.
As with
visual feedback, computer
games tend to excel at
positive audio
feedback.
Mac OS 9
also does a good job
with subtle positive audio
feedback for activities
like
documents
saves and drag and
drop. Of course, the audible
feedback must be at the
right
volume
for the situation. Windows and
the Mac offer a standard
volume control, so one
obstacle
to beneficial audible feedback has been
overcome.
Rich
modeless feedback is one of the greatest
tools at the disposal of
interaction
designers.
Replacing annoying, useless dialogs
with subtle and powerful
modeless
communication
can make the difference
between a program users will
despise and one they
will
love.
Think of all the ways
you might improve your own
applications with RVMF and
other
mechanisms
of modeless feedback!
Other
Communication with Users
43.2
This Part
of the lecture is about
communicating with your
users, and we would
be
remiss if
we did not discuss ways of
communicating to the user
that are not only
helpful
to them,
but which are also
helpful to you, as creator or
publisher of software, in
asserting
your brand and identity. In
the best circumstances,
these communications are
not at
odds, and this chapter
presents recommendations that will enable
you to make the
most
out of both aspects of user
communication.
Your
Identity on the
Desktop
The
modern desktop screen is
getting quite crowded. A
typical user has a
half-dozen
programs
running concurrently, and each
program must assert its
identity. The user
needs to
recognize your application when he has
relevant work to be done, and
you should
get the
credit you deserve for the
program you have created.
There are several
conventions
for
asserting identity in
software.
Your
program's name
By
convention, your program's name is
spelled out in the title
bar of the program's
main
window. This text value is
the program's title string, a single
text value within the
program
that is usually owned by the
program's main window.
Microsoft Windows
introduces
some complications. Since
Windows 95, the title
string has played a
greater
role in
the Windows interface. Particularly, the
title string is displayed on the
program's
launch
button on the taskbar.
The
launch buttons on the taskbar
automatically reduce their
size as more buttons are
added,
which happens as the number of open
programs increases. As the buttons
get
shorter,
their title strings are
truncated to fit.
Originally,
the title string contained only the
name of the application and
the company
brand name. Here's
the rub: If you add
your company's name to your program's
name,
like,
say "Microsoft Word," you
will find that it only takes
seven or eight running
programs
or open
folders to truncate your program's
launch-button string to "Microsoft." If
you
417

Human
Computer Interaction
(CS408)
VU
are also
running "Microsoft Excel,"
you will find two adjacent
buttons with
identical,
useless
title strings. The
differentiating portions of their names
-- "Word" and "Excel"
--
are
hidden.
The
title string has, over
the years, acquired another
purpose. Many programs use
it
to
display the name of the
currently active document.
Microsoft's Office
Suite
programs
do this. In Windows 95,
Microsoft appended the name
of the active document
to the
right end of the title
string, using a hyphen to separate it
from the program name.
In
subsequent
releases, Microsoft has
reversed that order: The
name of the document
comes
first, which is certainly a
more goal-directed choice 41 as
far as the user is
concerned.
The technique isn't a standard: but
because Microsoft does it,
it is often copied.
It makes
the title string extremely
long, far too long to fit
onto a launch
button-but
ToolTips
come to the rescue!
What
Microsoft could have done instead
was add a new title string
to the program's
internal
data structure. This string
would be used only on the
launch button (on
the
Taskbar),
leaving the original title
string for the window's
title bar. This enables
the
designer
and programmer to tailor the
launch-button string for its
restricted space,
while
letting
the title string languish
full-length on the always-roomier title
bar.
Your
program's icon
The
second biggest component of
your program's identity is
its icon. There are
two
icons to
worry about in Windows: the
standard one at 32 pixels square and a
miniature
one
that is 16 pixels square.
Mac OS 9 and earlier had a
similar arrangement; icons in OS
X
can
theoretically be huge -- up to 128x128
pixels. Windows XP also
seems to make use of
a 64x64
pixel, which makes sense
given that screen resolutions
today can exceed
1600x1200
pixels.
The 32x32
pixel size is used on the
desktop, and the 16x16
pixel icon is used on the
title bar,
the
taskbar, the Explorer, and at other
locations in the Windows interface.
Because of the
increased
importance of visual aesthetics in
contemporary GUIs, you must
pay greater
attention
to the quality of your
program icon. In particular,
you want your
program's
icon to
be readily identifiable from a distance
-- especially the miniature
version. The
user
doesn't necessarily have to be able to
recognize it outright -- although that
would
be nice --
but he should be able to readily see that
it is different from other
icons.
Icon
design is a craft unto
itself, and is more
difficult to do well than it
may appear.
Arguably,
Susan Kare's design of the
original Macintosh icons set
the standard in the
industry.
Today, many visual interface
designers specialize in the
design of icons, and
any
applications will
benefit from talent and experience
applied to the effort of icon
design.
Ancillary
Application Windows
Ancillary
application windows are
windows that are not really
part of the application's
functionality,
but are provided as a matter
of convention. These windows are
either
available
only on request or are offered up by
the program only once,
such as the
programs
credit screen. Those that
are offered unilaterally by
the program are erected
when
the program is used for
the very
first
time or each time the
program is initiated.
All these
windows, however, form channels of
communication that can both
help the
user
and better communicate your
brand.
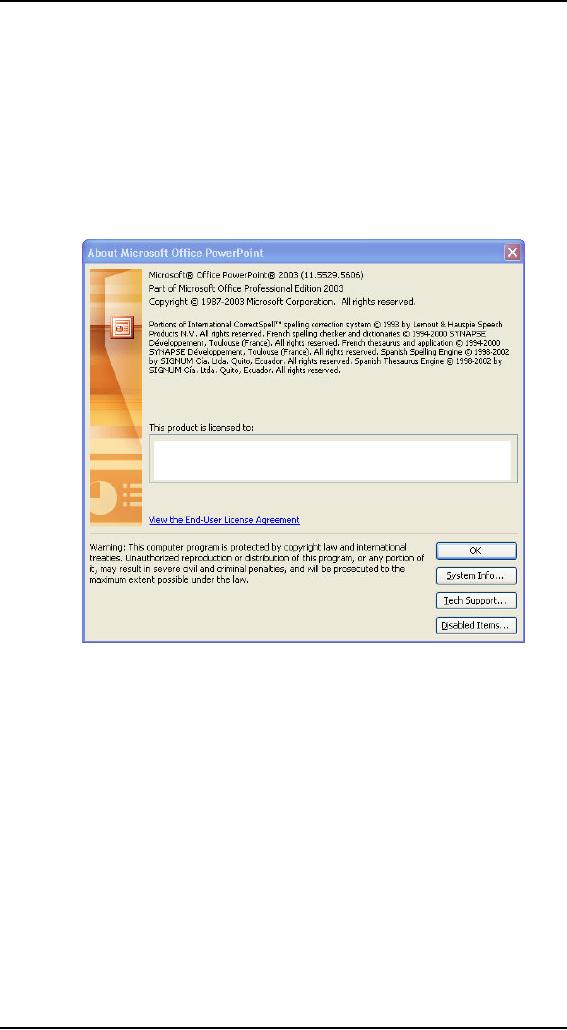
About
boxes
The
About box is a single dialog
box that -- by convention --
identifies the
program
to the
user. The About box is
also used as the program's
credit screen, identifying
the
418
Human
Computer Interaction
(CS408)
VU
people
who created it. Ironically,
the About box rarely
tells the user much about
the
program.
On the Macintosh, the About box
can be summoned from the top
of the Apple
pop-up
menu. In Windows, it is almost always
found at the bottom of the
Help menu.
Microsoft
has been consistent with
About boxes in its programs, and it has
taken a
simple
approach to its design, as
you can see in Figure
below. Microsoft uses
the
About
box almost exclusively as a
place for identification, a
sort of driver's license
for
software.
This is unfortunate, as it is a good
place to give the curious
user an overview
of the
program in a way that doesn't
intrude on those users who
don't need it. It is
often,
but not always, a good
thing to follow in Microsoft's design
footsteps. This is one
place where
diverging from Microsoft can
offer a big
advantage.
The
main problem with
Microsoft's approach is that
the About box doesn't tell
the
user
about' the program. In
reality, it is an identification box. It
identifies the
program
by name
and version number. It
identifies various s in
the program. It
identifies
the user and the
user's company. These are
certainly useful functions,
but
are more
useful for Microsoft customer
support than for the
user.
The
desire to make About boxes
more useful is clearly
strong -- otherwise, we
wouldn't
see, memory usage and
system-information buttons on them.
This is
admirable,
but, by taking a more ...
goal-directed approach, we can
add information to
the
About box that really
can help the user.
The single most important
thing that the
About
box can convey to the
user is the scope of the
program. It should tell, in
the
broadest terms,
what the program can
and can't do. It should also
state succinctly what
the
program does. Most program
authors forget that many
users don't have any
idea
what
the InfoMeister 3000 Version
4.0 program actually does.
This is the place to
gently
clue ,; them in.
419

Human
Computer Interaction
(CS408)
VU
The
About box is also a great
place to give the one lesson
that might start a new
user
success
fully. For example, if there
is one new idiom -- like a
direct-manipulation
method --
that is critical to the user
interaction, this is a good
place to briefly tell
him
about it. Additionally, the
About box can direct the new
user to other sources of
information
that will help him get his
bearings in the
program.
Because
the current design of this
facility just presents the
program's fine print instead
of
telling the user
about the
program, it should be called an Identity
box instead of an
About
box,
and that's how well
refer to it from this point
on. The Identity box
identifies the
program to the
user, " and the dialog in
Figure above fulfills this definition
admirably. It
tells us
all the stuff the
lawyers require and the tech
support people need to know.
Clearly,
Microsoft
has made the decision that an
Identity box is important,
whereas a true About
box is
expendable.
As we've
seen, the Identity box must
offer the basics of
identification, including
the
publisher's
name, the program's icons, the program's
version number, and the names
of
its
authors. Another item that
could profitably be placed here is the
publisher's technical
support telephone
number.
Many
software publishers don't
identify their programs with
sufficient discrimination
to tie ,
them to a specific software build. Some
vendors even go so far as to issue
the same
version
number to significantly different
programs for marketing reasons.
But the
version
number in the Identity -- or
About -- box is mainly used
by customer support. A
misleading version
number will cost the
publisher a significant amount of
phone-support
time
just figuring out precisely
which version of the program the user
has. It doesn't
matter
what scheme you use, as
long as this number is very
specific.
The
About box (not the
Identity box) is absolutely the
right place to state the
product
team's
names. The authors firmly
believe that credit should
be given where credit is due
in the design,
development, and testing of software.
Programmers, designers,
managers,
and
testers all deserve to see
their names in lights.
Documentation writers sometimes
get to
put their names in the
manual, but the others only
have the program itself. The
About
box is one of the few
dialogs that has no
functional overlap with the
main program,
so there
is no reason why it can't be
oversized. Take the space to mention
everyone who
contributed.
Although some programmers
are indifferent to seeing
their names on the
screen,
many programmers are
powerfully motivated by it and really
appreciate managers
who
make it happen. What possible
reason could there be for
not
naming
the smart, hard-
working
people who built the
program?
This
last question is directed at Bill Gates
(as it was in the first
edition in 1995), who
has a
corporate-wide policy that
individual programmers never
get to
put their names
in the
About boxes of programs. He
feels that it would be
difficult to know where to
draw
the
line with individuals. But
the credits for modern movies are
indicative that the
entertainment
industry, for one, has no
such worries. In fact, it is in game
software that
development
credits are most often
featured. Perhaps now that
Microsoft is heavy
into
the
game business things will change --
but don't count on
it.
Microsoft's
policy is disturbing because
its conventions are so
widely copied. As a
result,
Its
no-programmer-names
policy is also widely copied
by companies who have
no real
reason for it other than
blindly following
Microsoft.
420

Human
Computer Interaction
(CS408)
VU
Splash
screens
A splash
screen is a dialog box
displayed when a program first
loads into memory.
Sometimes
it may just be the About
box or Identity box,
displayed automatically,
but
more
often publishers create a
separate splash screen that is
more engaging and
visually
exciting.
The
splash screen should be
placed on the screen as soon as
user launches the
program,
so that he can view it while
the bulk of the program
loads and prepares itself
for
running.
After a few seconds have
passed, it should disappear
and the program
should
go about
its business. If, during the
splash screen's tenure, the
user presses any key
or
clicks
any mouse button, the
splash screen should disappear
immediately. The
program
must show
the utmost respect for the
user's time, even if it is
measured in milliseconds.
The
splash screen is an excellent
opportunity to create a good impression.
It can be used
to
reinforce the idea that
your users made a good
choice by purchasing your
product.
It also
helps to establish a visual brand by
displaying the company logo, the product
logo,
the
product icon, and other appropriate
visual symbols.
Splash
screens are also excellent
tools for directing
first-time users to training
resources
that
are not regularly used. If
the program has built-in
tutorials or configuration
options,
the
splash screen can provide
buttons that take the user
directly to these facilities
(in this
case, the
splash screen should remain
open until manually
dismissed).
Because
splash screens are going to
be seen by first-timers, if you
have something to say
to them,
this is a good place to do
it. On the other hand, the message
you offer to those
first-timers
will be annoying to experienced users, so
subsequent instances of the
splash
screen
should be more generic. Whatever you
say, be clear and terse,
not long-winded or
cute. An
irritating message on the
splash screen is like a pebble in
your shoe, rapidly
creating
a sore spot if it isn't removed
promptly.
Shareware
splash screens
If your
program is shareware, the splash screen
can be your most important
dialog
(though
not your users'). It is the
mechanism whereby you inform
users of the terms of
use
and the appropriate way to
pay for your product. Some
people refer to shareware splash
screens
as the guilt screen. Of
course, this information
should also be embedded in
the
program where the
user can request it,
but by presenting to users each
time the program
loads,
you can reinforce the
concept that the program should
be
paid for. On the
other
hand,
there's a fine line you need to
tread lest your sales
pitch alienate users. The
best
approach
is to create an excellent product, not to
guilt-trip potential
customers.
Online
help
Online
help is just like printed
documentation, a reference tool
for perpetual
intermediates.
Ultimately, online help is
not important, the way that
the user manual of
your
car is not important. If you
find yourself needing the manual, it
means that your car
is
badly
designed. The design is what
is important.
A complex
program with many features
and functions should come
with a reference
document:
a place where users who wish
to expand their horizons
with a product can
find
definitive
answers. This document can be a printed
manual or it can be online
help. The
printed
manual is comfortable, browsable,
friendly, and can be carried
around. The online
help is
searchable, semi-comfortable, very
lightweight, and
cheap.
421

Human
Computer Interaction
(CS408)
VU
The
index
Because
you don't read a manual like
a novel, the key to a
successful and
effective
reference
document is the quality of the tools
for finding what you
want in it.
Essentially,
this
means the index. A printed manual
has an index in the back that
you use manually.
Online
help has an automatic index
search facility.
The
experts suspect that few
online help facilities they've
seen were indexed by
a
professional
indexer. However many
entries are in your
program's index, you
could
probably
double the number. What's more, the
index needs to be generated by
examining
the
program and all its
features, not by examining the
help text This is not
easy, because it
demands
that a highly skilled
indexer be intimately familiar
with all the features of
the
program. It
may be easier to rework the
interface to improve it than to create a
really good
index.
The
list of index entries is
arguably more important than
the text of the
entries
themselves.
The user will forgive a
poorly written entry with
more alacrity than he will
forgive a
missing entry. The index must have as
many synonyms as possible
for topics.
Prepare
for it to be huge. The user
who needs to solve a problem
will be thinking "How
do I turn
this cell black?" not
"How can I set the
shading
of
this cell to 100%?" If
the
entry is
listed under shading, the
index fails the user.
The more goal-directed
your
thinking
is, the better the
index will map to what might
possibly pop into the
user's
head
when he is looking for something.
One index model that
works is the one in The
Joy
of
Cooking, Irma S.
Rombaur & Marion Rombaur Becker
(Bobbs-Merrill, 1962). That
index
is one of
the most complete and robust of any
the authors have used,
Shortcuts
and overview
One of
the features missing from
almost every help system is
a shortcuts option. It is
an item
in the Help menu which when
selected, shows in digest form
all the tools and
keyboard
commands for the program's
various features. It is a very
necessary component
on any
online help system because
it provides what perpetual intermediates
need the
most:
access to features. They
need the tools and commands
more than they need
detailed
instructions.
The other
missing ingredient from online
help systems is overview.
Users want to know
how
the Enter Macro command works,
and the help system explains
uselessly that it is
the
facility
that lets you enter macros
into the system. What we
need to know is scope,
effect,
power,
upside, downside, and why we
might want to use this
facility both in
absolute
terms
and in comparison to similar
products from other vendors.
@Last Software
provides
online streaming video
tutorials for its
architectural sketching
application,
SketchUp.
This is a fantastic approach to
overviews, particularly if they are
also available
on
CD-ROM.
Not
for beginners
Many
help systems assume that
their role is to provide
assistance to beginners. This
is
not
true. Beginners stay away
from the help system
because it is generally just as
complex
as the
program. Besides, any program whose
basic functioning is too hard to
figure out just
by experimentation is
unacceptable, and no amount of
help text will resurrect it.
Online
help
should ignore first-time
users and concentrate on those
people who are
already
successfully
using the product, but
who want to expand their horizons: the
perpetual
intermediates.
422

Human
Computer Interaction
(CS408)
VU
Modeless
and interactive help
ToolTips
are modeless online help,
and they are incredibly
effective. Standard
help
systems,
on the other hand, are implemented in a
separate program that covers up most
of
the
program for which it is offering
help. If you were to ask a human
how to perform a
task, he
would use his finger to
point to objects on the screen to augment
his explanation.
A
separate help program that
obscures the main program cannot do this.
Apple has used an
innovative
help system that directs
the user through a task
step by step by
highlighting
menus and
buttons that the user needs
to activate in sequence. Though
this is not totally
modeless,
it is interactive and closely integrated
with the task the user wants
to perform, and
not a
separate room, like reference
help systems,
Wizards
Wizards
are an idiom unleashed on
the world by Microsoft, and
they have rapidly
gained
popularity among programmers and user
interface designers. A wizard attempts
to
guarantee
success in using a feature by
stepping the user through a
series of dialog
boxes.
These dialogs parallel a
complex procedure that is "normally"
used to manage a
feature of
the program. For example, a wizard helps
the user create a presentation in
PowerPoint.
Programmers
like wizards because they get to treat
the user like a peripheral
device. Each
of the
wizard's dialogs asks the
user a question or two, and in the end
the program
performs whatever
task was requested. They
are a fine example of interrogation
tactics on
the
program's part, and violate
the axiom: Asking
questions isn't the same as
providing
choices.
Wizards
are written as step-by-step
procedures, rather than as informed
conversations
between
user and program. The user is
like the conductor of a robot orchestra,
swinging
the baton to
set the tempo, but otherwise
having no influence on the proceedings. In
this
way,
wizards rapidly devolve into
exercises in confirmation messaging.
The user learns
that he
merely clicks the Next button on
each screen without
critically analyzing why.
There is
a place for wizards in
actions that are very
rarely used, such as
installation
and
initial configuration. In the
weakly interactive world of HTML,
they have also
become
the standard idiom for almost
all transactions on the Web -- something
that
better browser
technology will eventually
change.
A better
way to create a wizard is to
make a simple, automatic function that
asks no
questions
of the user but that
just goes off and
does the job. If it creates
a presentation,
for
example, it should create it,
and then let the user
have the option, later, using
standard
tools, to
change the presentation. The
interrogation tactics of the typical
wizard are not
friendly,
reassuring, or particularly helpful. The
wizard often doesn't explain to the
user
what is
going on.
Wizards
were purportedly designed to
improve user interfaces, but
they are, in many
cases,
having
the opposite effect. They
are giving programmers
license to put raw
implementation
model interfaces on complex features with
the bland assurance that:
"We'll
make it
easy with a wizard." This is all too
reminiscent of the standard
abdication of
responsibility
to users: "We'll be sure to
document it in the manual."
"Intelligent"
agents
Perhaps
not much needs to be said
about Clippy and his
cousins, since even Microsoft
has
turned against their creation in its
marketing of Windows XP (not that it
has actually
removed
Clippy
from XP, mind you).
Clippy is a remnant of research
Microsoft did in the
423

Human
Computer Interaction
(CS408)
VU
creation
of BOB, an "intuitive" real-world,
metaphor-laden interface remarkably
similar to
General
Magic's Magic Cap interface.
BOB was populated with anthropomorphic,
animated
characters
that conversed with users to
help them accomplish things. It was
one of
Microsoft's
most spectacular interface failures.
Clippy is a descendant of these
help
agents
and is every bit as annoying
as they were.
A
significant issue with
"intelligent" animated agents is
that by employing animated
anthropomorphism,
the software is upping the
ante on user expectations of
the agent's
intelligence.
If it can't deliver on these
expectations, users will quickly
become furious, just
as they
would with a sales clerk in
a department store who
claims to be an expert on
his
products,
but who, after a few simple
questions, proves himself to be
clueless.
These constructs soon
become cloying and distracting. Users of
Microsoft Office are
trying to
accomplish something, not be entertained
by the antics and pratfalls
of the help
system.
Most applications demand more direct,
less distracting, and trustworthier
means of
getting
assistance.
Improving Data
Retrieval
43.3
In the
physical world, storing and
retrieving are inextricably linked;
putting an item
on a
shelf (storing it) also gives us the
means to find it later
(retrieving it}. In the
digital
world,
the only thing linking
these two concepts is our
faulty thinking. Computers will
enable
remarkably
sophisticated retrieval techniques if
only we are able to break
our thinking out of its
traditional
box. This part of lecture
discusses methods of data
retrieval from an
interaction
standpoint
and presents some more
human-centered approaches to the
problem of finding
useful
information.
Storage
and Retrieval Systems
A storage
system is a method for
safekeeping goods in a repository. It is
a physical
system
composed of a container and the
tools necessary to put
objects in and take
them
back out
again. A retrieval system is a method
for finding goods in a
repository. It is a logical
system
that allows the; goods to be
located according to some
abstract value, like
name,
position
or some aspect of the;
contents.
Disks and
files are usually rendered
in implementation terms rather than in
accord with the
user's
mental model of how information is
stored. This is also true in
the methods we use
for
finding
information
after it has been stored. This is
extremely unfortunate because
the
computer
is the one tool capable of
providing us with significantly
better methods of
finding
information than those
physically possible using
mechanical systems. But
before we talk
about
how to improve retrieval,
let's briefly discuss how it
works.
Storage
and Retrieval in the
Physical World
We can
own a book or a hammer
without giving it a name or a
permanent place of
residence
in our
houses. A book can be
identified by characteristics other than
a name -- a color
or a
shape, for example. However,
after we accumulate a large number of
items that we need
to find
and use, it helps to be a
bit more organized.
Everything
in its place: Storage and
retrieval by location
It is
important that there be a
proper place for our
books and hammers, because
that is
how we
find them when we need them.
We can't just whistle and expect
them to find us; we
must
know where they are and
then go there and fetch
them. In the physical world,
the
actual
location of a thing is the
means to finding it.
Remembering where we put
something-
-its
address -- is vital both to finding
it, and putting it away so it
can be found again. When
we
424

Human
Computer Interaction
(CS408)
VU
want to
find a spoon, for example,
we go to the place where we
keep our spoons. We don't
find the
spoon by
referring to any inherent
characteristic of the spoon
itself. Similarly, when
we
look
for a book, we either go to where we left
the book, or we guess that it is
stored
with
other books. We don't find the book by
association. That is, we
don't find the
book
by
referring to its contents.
In this
model, which works just
fine in your home, the
storage system is the same
as
the
retrieval system: Both are based on
remembering locations. They
are coupled
storage
and retrieval
systems.
Indexed
retrieval
This
system of everything in its
proper place sounds pretty
good, but it has a flaw:
It
is
limited in scale by human memory.
Although it works for the
books, hammers, and
spoons in
your house, it doesn't work
at all for the volumes stored, for
example, in the
Library
of Congress.
In the
world of hooks and paper on
library shelves, we make use of
another tool to
help us
find things: the Dewey
Decimal system (named after
its inventor,
American
philosopher
and educator John Dewey).
The idea was brilliant:
Give even' book title
a
unique
number based on its subject
matter and title and
shelve the books in
this
numerical
order. If you know the
number, you can easily
find the book, and
other
books
related to it by subject would be near by
-- perfect for research. The
only
remaining
issue was how to discover
the number for a given
book. Certainly
nobody
could be
expected to remember every
number.
The
solution was an index, a
collection of records that allows
you to find the
location
of an
item by looking up an attribute of
the item, such as its name.
Traditional library
card
catalogs provided lookup by three
attributes: author, subject,
and title. When
the
book is
entered into the library
system and assigned a
number, three index cards
are
created
for the book, including
all particulars and the
Dewey Decimal number.
Each
card is
headed by the author's name, the
subject, or the title. These
cards are then
placed in
their respective indices in
alphabetical order. When you
want to find a book,
you
look it up in one of the
indices and find its
number. You then find
the row of
shelves
that contains books with
numbers in the same range as your
target by
examining
signs. You search those particular
shelves, narrowing your view by
the
lexical
order of the numbers until
you find the one
you want.
You
physically
retrieve
the book by participating in
the system of storage, but
you
logically
find
the book you want by
participating in a system of retrieval.
The shelves and
numbers
are the storage system. The
card indices are the
retrieval system. You
identify the
desired
book with one and
fetch it w i t h the other. In a
typical university or
professional
library, customers are not
allowed into the stacks. As
a customer, you
identify
the book you want by
using only the retrieval
system. The librarian
then
fetches
the book for you by
participating only in the storage
system. The unique
serial
number is the
bridge between these two interdependent
systems. In the physical
world,
both
the retrieval system and
the storage system may be
very labor intensive.
Particularly
in older, non-computerized libraries,
they are both inflexible.
Adding a fourth
index
based on acquisition date,
for example, would be
prohibitively difficult for
the library.
Storage
and Retrieval in the Digital
World
Unlike in
the physical world of books,
stacks, and cards, it's
not very hard to add
an
index in
the computer. Ironically, in a
system where easily
implementing dynamic,
425

Human
Computer Interaction
(CS408)
VU
associative
retrieval mechanisms is at last
possible, we often don't
implement any
retrieval
system. Astonishingly, we don't
use indices at all on the
desktop.
In most of
today's computer systems,
there is no retrieval system
other than the
storage
system. If you want to find
a file on disk you need to
know its name and
its
place.
It's as if we went into the
library, burned the card
catalog, and told the
patrons
that
they could easily find
what they want by just
remembering the little
numbers
painted
on the spines of the books.
We have put 100 percent of
the burden of file
retrieval
on the user's memory while
the CPU just sits
there idling, executing
billions
of nop
instructions.
Although
our desktop computers can
handle hundreds of different
indices, we ignore
this
capability and have no
indices at all pointing into
the files stored on our
disks.
Instead,
we have to remember where we
put our files and
what we called them
in
order to
find them again. This
omission is one of the most
destructive, backward
steps
in modern
software design. This
failure can be attributed to
the interdependence of
files
and the organizational
systems in which they exist,
an interdependence that
doesn't
exist in the mechanical
world.
Retrieval
methods
There
are three fundamental ways
to find a document on a computer.
You can find it
by
remembering where you left
it in the file structure, by
positional retrieval. You
can
find it
by remembering its identifying name, by
identity retrieval. The
third method,
associative
or attributed-based retrieval, is based
on the ability to search for
a
document
based on some inherent
quality of the document
itself. For example, if
you
want to
find a book with a red
cover, or one that discusses
light rail transit systems,
or
one
that contains photographs of
steam locomotives, or one
that mentions
Theodore
Judah,
the method you must use is
associative.
Both
positional and identity retrieval are
methods that also function as
storage systems, and
on
computers,
which can sort reasonably
well by name, they are
practically one and the
same.
Associative retrieval is the one
method that is not also a
storage system. If our
retrieval
system is
based solely on storage methods, we deny
ourselves any attribute-based
searching
and we
must depend on memory. Our
user must know what
information he wants
and
where it
is stored in order to find
it. To find the spreadsheet
in which he calculated
the
amortization
of his home loan he has to
know that he stored it in
the directory called Home
and
that it was called amortl. If he doesn't
remember either of these facts,
finding the
document
can become quite
difficult
An
attribute-based retrieval
system
For
early GUI systems like the
original Macintosh, a positional
retrieval system
almost
made sense: The desktop
metaphor dictated it (you
don't use an index to
look
up papers
on your desk), and there
were precious few documents
that could be stored
on a 144K
floppy disk. However, our
current desktop systems can
now easily hold
250,000
times as many documents! Yet
we still use the same
metaphors and retrieval
model to
manage our data. We continue to
render our software's
retrieval systems in
strict
adherence to the implementation model of
the storage system, ignoring
the
power
and ease-of-use of a system for
finding files that is
distinct from the system
for
keeping
files.
An
attribute-based retrieval system would
enable us to find our documents by
their contents.
For
example, we could find all
documents that contain the
text string
426

Human
Computer Interaction
(CS408)
VU
"superelevation".
For such a search system to
really be effective, it should
know
where
all documents can be found, so
the user doesn't have to say
"Go look in such-
and-such a
directory and find all
documents that mention "superelevation."
This
system
would, of course, know a
little bit about the
domain of its search so it
wouldn't
try to
search the entire Internet,
for example, for
''superelevation" unless we
insist.
A
well-crafted, attribute-based retrieval
system would also enable
the user to browse
by
synonym or related topics or by
assigning attributes to individual
documents. The
user
can then & dynamically
define sets of documents having
these overlapping
attributes.
For example, imagine a
consulting business where
each potential client
is
sent a
proposal letter. Each of these
letters is different and is
naturally grouped
with
the
files pertinent to that
client. However, there is a
definite relationship between
each
of these
letters because they all
serve the same function:
proposing a business
relationship.
It would be very convenient if a
user could find and
gather up all such
proposal
letters while allowing each
one to retain its uniqueness
and association with
its
particular client. A file
system based on place --on
its single storage location
--
must of necessity
store each document by a single
attribute rather than
multiple
characteristics.
The
system can learn a lot
about each document just by
keeping its eyes and
ears
open. If
the attribute based
retrieval system remembers some of
this information,
much of
the setup burden on the user
is made unnecessary. The
program could, for
example,
easily remember such things
as:
� The
program that created the
document
� The
type of document: words, numbers,
tables, graphics
� The
program that last opened the
document.
� If
the document is exceptionally large or
small
� If
the document has been
untouched for a long
time
� The length of
time the document was
last open
� The
amount of information that was added or
deleted during the last
edit
� Whether
or not the document has
been edited by more than
one type of program
� Whether
the document contains
embedded objects from other
programs
� If
the document was created
from scratch or cloned from
another
� If
the document is frequently
edited
� If the document
is frequently viewed but
rarely edited
� Whether
the document has been
printed and where
� How
often the document has
been printed, and whether
changes were made to
it
each
timeimmediately before printing
� Whether
the document has been
faxed and to whom
� Whether
the document has been
e-mailed and to whom
The
retrieval system could find
documents for the user
based on these facts without
the
user
ever having to explicitly record anything
in advance. Can you think of
other useful
attributes
the system might
remember?
One
product on the market
provides much of this
functionality for Windows.
Enfish
Corporation
sells a suite of personal and
enterprise products that
dynamically and
invisibly
create an index of information on
your computer system, across
a LAN if
427

Human
Computer Interaction
(CS408)
VU
you
desire it (the Professional
version), and even across
the Web. It tracks
documents,
bookmarks,
contacts, and e-mails -- extracting
all the reasonable attributes. It
also
provides
powerful sorting and
filtering capability. It is truly a
remarkable set of
products.
We should all learn from
the Enfish example.
There is
nothing wrong with the
disk file storage systems
that we have created
for
ourselves.
The only problem is that we
have failed to create adequate
disk file
retrieval
systems. Instead, we hand
the user the storage system
and call it a
retrieval
system.
This is like handing him a
bag of groceries and calling
it a gourmet dinner.
There is
no reason to change our file storage
systems. The Unix model is
fine. Our
programs
can easily remember the
names and locations of the
files they have
worked
on, so
they aren't the ones
who need a retrieval system: It's
for us human users.
428
Table of Contents:
- RIDDLES FOR THE INFORMATION AGE, ROLE OF HCI
- DEFINITION OF HCI, REASONS OF NON-BRIGHT ASPECTS, SOFTWARE APARTHEID
- AN INDUSTRY IN DENIAL, SUCCESS CRITERIA IN THE NEW ECONOMY
- GOALS & EVOLUTION OF HUMAN COMPUTER INTERACTION
- DISCIPLINE OF HUMAN COMPUTER INTERACTION
- COGNITIVE FRAMEWORKS: MODES OF COGNITION, HUMAN PROCESSOR MODEL, GOMS
- HUMAN INPUT-OUTPUT CHANNELS, VISUAL PERCEPTION
- COLOR THEORY, STEREOPSIS, READING, HEARING, TOUCH, MOVEMENT
- COGNITIVE PROCESS: ATTENTION, MEMORY, REVISED MEMORY MODEL
- COGNITIVE PROCESSES: LEARNING, READING, SPEAKING, LISTENING, PROBLEM SOLVING, PLANNING, REASONING, DECISION-MAKING
- THE PSYCHOLOGY OF ACTIONS: MENTAL MODEL, ERRORS
- DESIGN PRINCIPLES:
- THE COMPUTER: INPUT DEVICES, TEXT ENTRY DEVICES, POSITIONING, POINTING AND DRAWING
- INTERACTION: THE TERMS OF INTERACTION, DONALD NORMAN’S MODEL
- INTERACTION PARADIGMS: THE WIMP INTERFACES, INTERACTION PARADIGMS
- HCI PROCESS AND MODELS
- HCI PROCESS AND METHODOLOGIES: LIFECYCLE MODELS IN HCI
- GOAL-DIRECTED DESIGN METHODOLOGIES: A PROCESS OVERVIEW, TYPES OF USERS
- USER RESEARCH: TYPES OF QUALITATIVE RESEARCH, ETHNOGRAPHIC INTERVIEWS
- USER-CENTERED APPROACH, ETHNOGRAPHY FRAMEWORK
- USER RESEARCH IN DEPTH
- USER MODELING: PERSONAS, GOALS, CONSTRUCTING PERSONAS
- REQUIREMENTS: NARRATIVE AS A DESIGN TOOL, ENVISIONING SOLUTIONS WITH PERSONA-BASED DESIGN
- FRAMEWORK AND REFINEMENTS: DEFINING THE INTERACTION FRAMEWORK, PROTOTYPING
- DESIGN SYNTHESIS: INTERACTION DESIGN PRINCIPLES, PATTERNS, IMPERATIVES
- BEHAVIOR & FORM: SOFTWARE POSTURE, POSTURES FOR THE DESKTOP
- POSTURES FOR THE WEB, WEB PORTALS, POSTURES FOR OTHER PLATFORMS, FLOW AND TRANSPARENCY, ORCHESTRATION
- BEHAVIOR & FORM: ELIMINATING EXCISE, NAVIGATION AND INFLECTION
- EVALUATION PARADIGMS AND TECHNIQUES
- DECIDE: A FRAMEWORK TO GUIDE EVALUATION
- EVALUATION
- EVALUATION: SCENE FROM A MALL, WEB NAVIGATION
- EVALUATION: TRY THE TRUNK TEST
- EVALUATION – PART VI
- THE RELATIONSHIP BETWEEN EVALUATION AND USABILITY
- BEHAVIOR & FORM: UNDERSTANDING UNDO, TYPES AND VARIANTS, INCREMENTAL AND PROCEDURAL ACTIONS
- UNIFIED DOCUMENT MANAGEMENT, CREATING A MILESTONE COPY OF THE DOCUMENT
- DESIGNING LOOK AND FEEL, PRINCIPLES OF VISUAL INTERFACE DESIGN
- PRINCIPLES OF VISUAL INFORMATION DESIGN, USE OF TEXT AND COLOR IN VISUAL INTERFACES
- OBSERVING USER: WHAT AND WHEN HOW TO OBSERVE, DATA COLLECTION
- ASKING USERS: INTERVIEWS, QUESTIONNAIRES, WALKTHROUGHS
- COMMUNICATING USERS: ELIMINATING ERRORS, POSITIVE FEEDBACK, NOTIFYING AND CONFIRMING
- INFORMATION RETRIEVAL: AUDIBLE FEEDBACK, OTHER COMMUNICATION WITH USERS, IMPROVING DATA RETRIEVAL
- EMERGING PARADIGMS, ACCESSIBILITY
- WEARABLE COMPUTING, TANGIBLE BITS, ATTENTIVE ENVIRONMENTS